IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019
Speech2face: learning the face behind a voice, supplementary material.
In this supplementary, we show the input audio results that cannot be included in the main paper as well as large number of additional qualitative results. The input audio can be played in the browser (tested on Chrome version >= 70.0 and HTML5 recommended).
** Headphones recommended **
Additional 500 randomly-sampled results on AVSpeech can be found | |
|
| |
|
Additional 100 randomly-sampled S2F-based retrieval results can be found | |
|
| |

Figure 1: Teaser
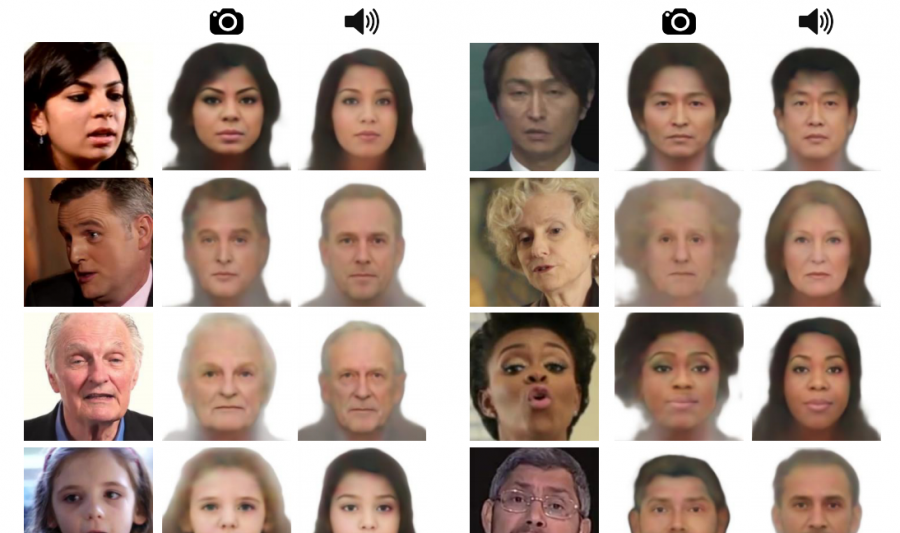
Teaser results on the VoxCeleb dataset. Several results of our method are shown. The true faces are shown just for reference; our model takes only an audio waveform as input. Note that our goal is not to reconstruct an accurate image of the person, but rather to recover characteristic physical features that are correlated with the input speech.
To the top.
Figure 3: Qualitative results on the AVSpeech
Qualitative results on the AVSpeech test set. For every example (triplet of images) we show: (left) the original image, i.e., a representative frame from the video cropped around the speaker’s face; (middle) the frontalized, lighting-normalized face decoder reconstruction from the VGG-Face feature extracted from the original image; (right) our Speech2Face reconstruction, computed by decoding the predicted VGG-Face feature from the audio. In this figure, we highlight successful results of our method. Some failure cases are shown in Fig. 12.
See additional 500 randomly-sampled results on AVSpeech here .
Figure 4: Facial attribute evaluation

Attribute confusion matrix between original face image and face reconstruction from face feature. In the main paper, we show the facial attribute confusion matrices comparing the classification results on our Speech2Face image reconstructions and those obtained from the original images for gender, age, and ethnicity. Due to the domain gap between the original image and reconstructed faces, the usage of the existing classifier (Face++) may introduce some bias in the result. In this supplementary material, we show the confusion matrices comparing the classification results on face reconstructions from the original images and those obtained from the original images for reference to see the performance deviation sourced by the face decoder module. Please compare with Figure 4 in the main paper. The performance along diagonal entries can be considered as a pseudo upper bound of the performance of the confusion matrices in Figure 4. The confusion matrices are row-wise normalized, and strong diagonal tendency indicates better performance. We evaluate the attribute over the AVSpeech test set, which is consistent with Figure 4.
Figure 5: Craniofacial feature
Craniofacial features. We measure the correlation between craniofacial features extracted from (a) face decoder reconstructions from the original image (F2F), and (b) features extracted from our corresponding Speech2Face reconstructions (S2F); the features are computed from detected facial landmarks, as described in [30]. The table reports Pearson correlation coefficient and statistical significance computed over 1,000 test images for each feature. Random baseline is computed for “Nasal index” by comparing random pairs of F2F reconstruction (a) and S2F reconstruction (b).
Figure 6: The effect of input audio duration
| 3 seconds | ||||||
| 6 seconds | ||||||
The effect of input audio duration. We compare our face reconstructions when using 3-second (middle row) and 6- second (bottom row) input voice segments at test time (in both cases we use the same model, trained on 6-second segments). The top row shows representative frames from the videos for reference. With longer speech duration the reconstructed faces capture the facial attributes better.
Figure 7: S2F-based retrieval
S2F => Face retrieval examples. We query a database of 5,000 face images by comparing our Speech2Face prediction of input audio to all VGG-Face face features in the database (computed directly from the original faces). For each query, we show the top-5 retrieved samples. The last row is an example where the true face was not among the top results, but still shows visually close results to the query. In this figure, we highlight successful results of our method, and mark ground-truth matches by red color.
See additional 100 randomly-sampled S2F-based retrieval results here .
Figure 8: Comparisons to a pixel loss
Comparisons to a pixel loss. The results obtained with an L1 loss on the output image and our full loss (Eq. 1) are shown after 300k and 500k training iterations (indicating convergence).
Figure 10: Temporal and cross-video consistency
| (a) | (b) | |||
Temporal and cross-video consistency. Face reconstruction from different speech segments of the same person taken from different parts within (a) the same or from (b) a different video.
Figure 11: The effect of language
| (a) An Asian male speaking in English (left) & Chinese (right) | (b) An Asian girl speaking in English | |||
The effect of language. We notice mixed performance in terms of the ability of the model to handle languages and accents. (a) A sample case of language-dependent face reconstructions. (b) A sample case that successfully factors out the language.
Figure 12: Failure cases
| (a) Gender mismatch | (c) Age mismatch (old to young) | |||
| (b) Ethnicity mismatch | (d) Age mismatch (young to old) | |||
Example failure cases. (a) High-pitch male voice, e.g., of kids, may lead to a face image with female features. (b) Spoken language does not match ethnicity. (c-d) Age mismatches.
Figure 13: Speech-to-cartoon
| (a) | (b) | (c) |
Speech-to-cartoon. Our reconstructed faces from audio (b) can be re-rendered as cartoons (c) using existing tools, such as the personalized emoji app available in Gboard , the keyboard app in Android phones. (a) The true images of the person are shown for reference.
Figure 14: Visualizing the feature space
In the main paper we show the t-SNE embeddings for the features of VoxCeleb samples. Here we show the t-SNE of AVSpeech samples.

Visualizing the features space (AVSpeech). t-SNE visualizations of the AVSpeech samples for the face features obtained from the original images by feeding them into VGG-Face (red boxes), and for the features predicted by our voice encoder (green boxes). We use the same computed projections for each feature type, but in each plot color-code the data points using a different attribute (from left to right: gender, age, and ethnicity). We use the AVSpeech dataset and the attribute annotations obtained using the gender, age, and ethnicity classifiers available from the Face++ service (not used for training). Notice for example how gender is the major distinctive feature in our learned feature space, dividing the space into two separated clusters, as for the samples taken from the VoxCeleb dataset shown in Fig. 11 of the main paper. The face features (red boxes) show local clusters to a lesser degree than those of the VoxCeleb dataset, since the AVSpeech dataset includes a larger number of identities. *These labels are as obtained from the Face++ ethnicity classifier.
Speech2Face
When we hear a voice on the radio or the phone, we often build a mental model for the way that person looks. Is that sort of intuition something that computers can develop too?
A team led by researchers from MIT’s Computer Science and Artificial Intelligence Lab (CSAIL) have recently shown that it can: they’ve created a new system that can produce a predicted image of someone’s face from hearing them talk for only five seconds.

Trained on millions of YouTube clips featuring over 100,000 different speakers, Speech2Face listens to audio of speech and compares it to other audio it’s heard. It can then create an image based on the facial characteristics most common to similar audio clips. The system was found to predict gender with ___ percent accuracy, age with , ___ percent accuracy, and race with ____ percent accuracy.
On top of that, the researchers even found correlations between speech and jaw shape - suggesting that Speech2Face could help scientists glean insights into the physiological connections between facial structure and speech. The team also combined Speech2Face with Google’s personalized emoji app to create “Speech2Cartoon,” which can turn the predicted face from live-action to cartoon.

Does not support

Speech2Face: Learning the Face Behind a Voice
How much can we infer about a person’s looks from the way they speak? In this paper, we study the task of reconstructing a facial image of a person from a short audio recording of that person speaking. We design and train a deep neural network to perform this task using millions of natural Internet/YouTube videos of people speaking. During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how—and in what manner—our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.
1 Introduction
When we listen to a person speaking without seeing his/her face, on the phone, or on the radio, we often build a mental model for the way the person looks [ 25 , 45 ] . There is a strong connection between speech and appearance, part of which is a direct result of the mechanics of speech production: age, gender (which affects the pitch of our voice), the shape of the mouth, facial bone structure, thin or full lips—all can affect the sound we generate. In addition, other voice-appearance correlations stem from the way in which we talk: language, accent, speed, pronunciations—such properties of speech are often shared among nationalities and cultures, which can in turn translate to common physical features [ 12 ] .
Our goal in this work is to study to what extent we can infer how a person looks from the way they talk. Specifically, from a short input audio segment of a person speaking, our method directly reconstructs an image of the person’s face in a canonical form (i.e., frontal-facing, neutral expression). Fig. 1 shows sample results of our method. Obviously, there is no one-to-one matching between faces and voices. Thus, our goal is not to predict a recognizable image of the exact face, but rather to capture dominant facial traits of the person that are correlated with the input speech.

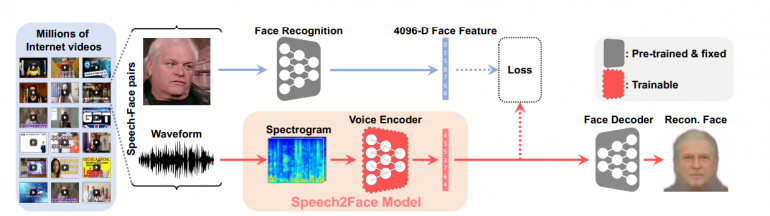
We design a neural network model that takes the complex spectrogram of a short speech segment as input and predicts a feature vector representing the face. More specifically, face information is represented by a 4096-D feature that is extracted from the penultimate layer (i.e., one layer prior to the classification layer) of a pre-trained face recognition network [ 40 ] . We decode the predicted face feature into a canonical image of the person’s face using a separately-trained reconstruction model [ 10 ] . To train our model, we use the AVSpeech dataset [ 14 ] , comprised of millions of video segments from YouTube with more than 100,000 different people speaking. Our method is trained in a self-supervised manner, i.e., it simply uses the natural co-occurrence of speech and faces in videos, not requiring additional information, e.g., human annotations.
We are certainly not the first to attempt to infer information about people from their voices. For example, predicting age and gender from speech has been widely explored [ 53 , 18 , 16 , 7 , 50 ] . Indeed, one can consider an alternative approach to attaching a face image to an input voice by first predicting some attributes from the person’s voice (e.g., their age, gender, etc. [ 53 ] ), and then either fetching an image from a database that best fits the predicted set of attributes, or using the attributes to generate an image [ 52 ] . However, this approach has several limitations. First, predicting attributes from an input signal relies on the existence of robust and accurate classifiers and often requires ground truth labels for supervision. For example, predicting age, gender or ethnicity from speech requires building classifiers specifically trained to capture those properties. More importantly, this approach limits the predicted face to resemble only a predefined set of attributes.
We aim at studying a more general, open question: what kind of facial information can be extracted from speech? Our approach of predicting full visual appearance (e.g., a face image) directly from speech allows us to explore this question without being restricted to predefined facial traits. Specifically, we show that our reconstructed face images can be used as a proxy to convey the visual properties of the person including age, gender and ethnicity. Beyond these dominant features, our reconstructions reveal non-negligible correlations between craniofacial features [ 31 ] (e.g., nose structure) and voice. This is achieved with no prior information or the existence of accurate classifiers for these types of fine geometric features. In addition, we believe that predicting face images directly from voice may support useful applications, such as attaching a representative face to phone/video calls based on the speaker’s voice.
To our knowledge, our work is the first to explore a generic (speaker independent) model for reconstructing face images directly from speech. We test our model on various speakers and numerically evaluate different aspects of our reconstructions including: how well a true face image can be retrieved based solely on an audio query; and how well our reconstructed face images agree with the true face images (unknown to the method) in terms of age, gender, ethnicity, and various craniofacial measures and ratios.
2 Ethical Considerations
Although this is a purely academic investigation, we feel that it is important to explicitly discuss in the paper a set of ethical considerations due to the potential sensitivity of facial information.
As mentioned, our method cannot recover the true identity of a person from their voice (i.e., an exact image of their face). This is because our model is trained to capture visual features (related to age, gender, etc.) that are common to many individuals, and only in cases where there is strong enough evidence to connect those visual features with vocal/speech attributes in the data (see “voice-face correlations” below). As such, the model will only produce average-looking faces, with characteristic visual features that are correlated with the input speech. It will not produce images of specific individuals.
Voice-face correlations and dataset bias.
Our model is designed to reveal statistical correlations that exist between facial features and voices of speakers in the training data. The training data we use is a collection of educational videos from YouTube [ 14 ] , and does not represent equally the entire world population. Therefore, the model—as is the case with any machine learning model—is affected by this uneven distribution of data.
More specifically, if a set of speakers might have vocal-visual traits that are relatively uncommon in the data, then the quality of our reconstructions for such cases may degrade. For example, if a certain language does not appear in the training data, our reconstructions will not capture well the facial attributes that may be correlated with that language.
Note that some of the features in our predicted faces may not even be physically connected to speech, for example hair color or style. However, if many speakers in the training set who speak in a similar way (e.g., in the same language) also share some common visual traits (e.g., a common hair color or style), then those visual traits may show up in the predictions.
For the above reasons, we recommend that any further investigation or practical use of this technology will be carefully tested to ensure that the training data is representative of the intended user population. If that is not the case, more representative data should be broadly collected.
Categories.
In our experimental section, we mention inferred demographic categories such as “White” and “Asian”. These are categories defined and used by a commercial face attribute classifier [ 15 ] , and were only used for evaluation in this paper. Our model is not supplied with and does not make use of this information at any stage.
3 Related Work
| Layer | CONV | CONV | CONV | CONV | CONV | CONV | CONV | CONV | AVGPOOL | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Input | RELU | RELU | RELU | MAXPOOL | RELU | MAXPOOL | RELU | MAXPOOL | RELU | MAXPOOL | RELU | RELU | CONV | RELU | FC | FC | |
| BN | BN | BN | BN | BN | BN | BN | BN | BN | RELU | ||||||||
| Channels | 2 | 64 | 64 | 128 | – | 128 | – | 128 | – | 256 | – | 512 | 512 | 512 | – | 4096 | 4096 |
| Stride | – | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 1 | 1 | 1 | ||||
| Kernel size | – |
Audio-visual cross-modal learning.
The natural co-occurrence of audio and visual signals often provides rich supervision signal, without explicit labeling, also known as self-supervision [ 11 ] or natural supervision [ 24 ] . Arandjelović and Zisserman [ 4 ] leveraged this to learn a generic audio-visual representations by training a deep network to classify if a given video frame and a short audio clip correspond to each other. Aytar et al . [ 6 ] proposed a student-teacher training procedure in which a well established visual recognition model was used to transfer the knowledge obtained in the visual modality to the sound modality, using unlabeled videos. Similarly, Castrejon et al . [ 8 ] designed a shared audio-visual representation that is agnostic of the modality. Such learned audio-visual representations have been used for cross-modal retrieval [ 38 , 39 , 46 ] , sound source localization [ 42 , 5 , 37 ] , and sound source separation [ 54 , 14 ] . Our work utilizes the natural co-occurrence of faces and voices in Interent videos. We use a pre-trained face recognition network to transfer facial information to the voice modality.
Speech-face association learning.
The associations between faces and voices have been studied extensively in many scientific disciplines. In the domain of computer vision, different cross-modal matching methods have been proposed: a binary or multi-way classification task [ 34 , 33 , 44 ] ; metric learning [ 27 , 21 ] ; and the multi-task classification loss [ 50 ] . Cross-modal signals extracted from faces and voices have been used to disambiguate voiced and unvoiced consonants [ 36 , 9 ] ; to identify active speakers of a video from non-speakers therein [ 20 , 17 ] ; to separate mixed speech signals of multiple speakers [ 14 ] ; to predict lip motions from speech [ 36 , 3 ] ; or to learn the correlation between speech and emotion [ 2 ] . Our goal is to learn the correlations between facial traits and speech, by directly reconstructing a face image from a short audio segment.
Visual reconstruction from audio.
Various methods have been recently proposed to reconstruct visual information from different types of audio signals. In a more graphics-oriented application, automatic generation of facial or body animations from music or speech has been gaining interest [ 48 , 26 , 47 , 43 ] . However, such methods typically parametrize the reconstructed subject a priori, and its texture is manually created or mined from a collection of textures. In the context of pixel-level generative methods, Sadoughi and Busso [ 41 ] reconstruct lip motions from speech, and Wiles et al . [ 51 ] control the pose and expression of a given face using audio (or another face). While not directly related to audio, Yan et al. [ 52 ] and Liu and Tuzel [ 30 ] synthesize a face image from given facial attributes as input. Our model reconstructs a face image directly from speech, with no additional information. Finally, Duarte et al . [ 13 ] synthesize face images from speech using a GAN model, but their goal is to recover the true face of the speaker including expression and pose. In contrast, our goal is to recover general facial traits, i.e., average looking faces in canonical pose and expression but capturing dominant visual attributes across many speakers.

4 Speech2Face (S2F) Model
The large variability in facial expressions, head poses, occlusions, and lighting conditions in natural face images makes the design and training of a Speech2Face model non-trivial. For example, a straightforward approach of regressing from input speech to image pixels does not work; such a model has to learn to factor out many irrelevant variations in the data and to implicitly extract a meaningful internal representation of faces—a challenging task by itself.
To sidestep these challenges, we train our model to regress to a low-dimensional intermediate representation of the face. More specifically, we utilize the VGG-Face model, a face recognition model pre-trained on a large-scale face dataset [ 40 ] , and extract a 4096-D face feature from the penultimate layer ( fc7 ) of the network. These face features were shown to contain enough information to reconstruct the corresponding face images while being robust to many of the aforementioned variations [ 10 ] .
Our Speech2Face pipeline, illustrated in Fig. 2 , consists of two main components: 1) a voice encoder, which takes a complex spectrogram of speech as input, and predicts a low-dimensional face feature that would correspond to the associated face; and 2) a face decoder, which takes as input the face feature and produces an image of the face in a canonical form (frontal-facing and with neutral expression). During training, the face decoder is fixed, and we train only the voice encoder that predicts the face feature. The voice encoder is a model we designed and trained, while we used a face decoder model proposed by Cole et al . [ 10 ] . We now describe both models in detail.

(a) Confusion matrices for the attributes (b) AVSpeech dataset statistics
Voice encoder network.
Our voice encoder module is a convolutional neural network that turns the spectrogram of a short input speech into a pseudo face feature, which is subsequently fed into the face decoder to reconstruct the face image (Fig. 2 ). The architecture of the voice encoder is summarized in Table 1 . The blocks of a convolution layer, ReLU, and batch normalization [ 23 ] alternate with max-pooling layers, which pool along only the temporal dimension of the spectrograms, while leaving the frequency information carried over. This is intended to preserve more of the vocal characteristics, since they are better contained in the frequency content, whereas linguistic information usually spans longer time duration [ 22 ] . At the end of these blocks, we apply average pooling along the temporal dimension. This allows us to efficiently aggregate information over time and makes the model applicable to input speech of varying duration. The pooled features are then fed into two fully-connected layers to produce a 4096-D face feature.
Face decoder network.
The goal of the face decoder is to reconstruct the image of a face from a low-dimensional face feature. We opt to factor out any irrelevant variations (pose, lighting, etc.), while preserving the facial attributes. To do so, we use the face decoder model of Cole et al . [ 10 ] to reconstruct a canonical face image. We train this model using the same face features extracted from the VGG-Face model as input to the face decoder. This model is trained separately and kept fixed during the voice encoder training.
Our voice encoder is trained in a self-supervised manner, using the natural co-occurrence of a speaker’s speech and facial images in videos. To this end, we use the AVSpeech dataset [ 14 ] , a large-scale “in-the-wild” audiovisual dataset of people speaking. A single frame containing the speaker’s face is extracted from each video clip and fed to the VGG-Face model to extract the 4096-D feature vector, 𝐯 f subscript 𝐯 𝑓 \mathbf{v}_{\!f} . This serves as the supervision signal for our voice encoder—the feature, 𝐯 s subscript 𝐯 𝑠 \mathbf{v}_{\!s} , of our voice encoder is trained to predict 𝐯 f subscript 𝐯 𝑓 \mathbf{v}_{\!f} .
A natural choice for the loss function would be the L 1 subscript 𝐿 1 L_{1} distance between the features: ‖ 𝐯 f − 𝐯 s ‖ 1 subscript norm subscript 𝐯 𝑓 subscript 𝐯 𝑠 1 \left\|\mathbf{v}_{\!f}-\mathbf{v}_{\!s}\right\|_{1} . However, we found that the training undergoes slow and unstable progression with this loss alone. To stabilize the training, we introduce additional loss terms, motivated by Castrejon et al. [ 8 ] . Specifically, we additionally penalize the difference in the activation of the last layer of the face encoder, f VGG : ℝ 4096 → ℝ 2622 : subscript 𝑓 VGG → superscript ℝ 4096 superscript ℝ 2622 f_{\texttt{VGG}}:\mathbb{R}^{4096}\rightarrow\mathbb{R}^{2622} , i.e., fc8 of VGG-Face, and that of the first layer of the face decoder, f dec : ℝ 4096 → ℝ 1000 : subscript 𝑓 dec → superscript ℝ 4096 superscript ℝ 1000 f_{\texttt{dec}}:\mathbb{R}^{4096}{\rightarrow}\mathbb{R}^{1000} , which are pre-trained and fixed during training the voice encoder. We feed both our predictions and the ground truth face features to these layers to calculate the losses. The final loss is:
| (1) | |||||
where λ 1 = 0.025 subscript 𝜆 1 0.025 \lambda_{1}{=}0.025 and λ 2 = 200 subscript 𝜆 2 200 \lambda_{2}{=}200 . λ 1 subscript 𝜆 1 \lambda_{1} and λ 2 subscript 𝜆 2 \lambda_{2} are tuned such that the gradient magnitude of each term with respect to 𝐯 s subscript 𝐯 𝑠 \mathbf{v}_{\!s} are within a similar scale at an early iteration (we measured at the 1000th iteration). The knowledge distillation loss L distill ( 𝐚 , 𝐛 ) = − ∑ i p ( i ) ( 𝐚 ) log p ( i ) ( 𝐛 ) subscript 𝐿 distill 𝐚 𝐛 subscript 𝑖 subscript 𝑝 𝑖 𝐚 subscript 𝑝 𝑖 𝐛 L_{\mathrm{distill}}(\mathbf{a},\mathbf{b})=-\!\sum_{i}p_{(i)}(\mathbf{a})\log p_{(i)}(\mathbf{b}) , where p ( i ) ( 𝐚 ) = exp ( a i / T ) ∑ j exp ( a j / T ) subscript 𝑝 𝑖 𝐚 subscript 𝑎 𝑖 𝑇 subscript 𝑗 subscript 𝑎 𝑗 𝑇 p_{(i)}(\mathbf{a})=\tfrac{\exp(a_{i}/T)}{\sum_{j}{\exp(a_{j}/T)}} , is used as an alternative of the cross entropy loss, which encourages the output of a network to approximate the output of another [ 19 ] . T = 2 𝑇 2 T{=}2 is used as recommended by the authors, which makes the activation smoother. We found that enforcing similarity over these additional layers stabilized and sped up the training process, in addition to a slight improvement in the resulting quality.
Implementation details.
We use up to 6 seconds of audio taken from the beginning of each video clip in AVSpeech. If the video clip is shorter than 6 seconds, we repeat the audio such that it becomes at least 6-seconds long. The audio waveform is resampled at 16 kHz and only a single channel is used. Spectrograms are computed similarly to Ephrat et al. [ 14 ] by taking STFT with a Hann window of 25 mm, the hop length of 10 ms, and 512 FFT frequency bands. Each complex spectrogram S 𝑆 S subsequently goes through the power-law compression, resulting sgn ( S ) | S | 0.3 sgn 𝑆 superscript 𝑆 0.3 \mathrm{sgn}(S)|S|^{0.3} for real and imaginary independently, where sgn ( ⋅ ) sgn ⋅ \mathrm{sgn}(\cdot) denotes the signum. We run the CNN-based face detector from Dlib [ 28 ] , crop the face regions from the frames, and resize them to 224 × \times 224 pixels. The VGG-Face features are computed from the resized face images. The computed spectrogram and VGG-Face feature of each segment are collected and used for training. The resulting training and test sets include 1.7 and 0.15 million spectra–face feature pairs, respectively. Our network is implemented in TensorFlow and optimized by ADAM [ 29 ] with β 1 = 0.5 subscript 𝛽 1 0.5 \beta_{1}=0.5 , ϵ = 10 − 4 italic-ϵ superscript 10 4 \epsilon=10^{-4} , the learning rate of 0.001 with the exponentially decay rate of 0.95 at every 10,000 iterations, and the batch size of 8 for 3 epochs.
We test our model both qualitatively and quantitatively on the AVSpeech dataset [ 14 ] and the VoxCeleb dataset [ 35 ] . Our goal is to gain insights and to quantify how—and in which manner—our Speech2Face reconstructions resemble the true face images.
Qualitative results on the AVSpeech test set are shown in Fig. 3 . For each example, we show the true image of the speaker for reference (unknown to our model), the face reconstructed from the face feature (computed from the true image) by the face decoder (Sec. 4 ), and the face reconstructed from a 6-seconds audio segment of the person’s speech, which is our Speech2Face result. While looking somewhat like average faces, our Speech2Face reconstructions capture rich physical information about the speaker, such as their age, gender, and ethnicity. The predicted images also capture additional properties like the shape of the face or head (e.g., elongated vs. round), which we often find consistent with the true appearance of the speaker; see the last two rows in Fig. 3 for instance.
5.1 Facial Features Evaluation
We quantify how well different facial attributes are being captured in our Speech2Face reconstructions and test different aspects of our model.
Demographic attributes.
We use Face++ [ 15 ] , a leading commercial service for computing facial attributes. Specifically, we evaluate and compare age, gender, and ethnicity, by running the Face++ classifiers on the original images and our Speech2Face reconstructions. The Face++ classifiers return either “male” or “female” for gender, a continuous number for age, and one of the four values, “Asian”, “black”, “India”, or “white”, for ethnicity. 1 1 1 We directly refer to the Face++ labels, which are not our terminology.

| Face measurement | Correlation | -value |
|---|---|---|
| Upper lip height | 0.16 | |
| Lateral upper lip heights | 0.26 | |
| Jaw width | 0.11 | |
| Nose height | 0.14 | |
| Nose width | 0.35 | |
| Labio oral region | 0.17 | |
| Mandibular idx | 0.20 | |
| Intercanthal idx | 0.21 | |
| Nasal index | 0.38 | |
| Vermilion height idx | 0.29 | |
| Mouth face with idx | 0.20 | |
| Nose area | 0.28 | |
| Random baseline | 0.02 | – |
(c) Pearson correlation coefficient
Fig. 4 (a) shows confusion matrices for each of the attributes, comparing the attributes inferred from the original images with those inferred from our Speech2Face reconstructions (S2F). See the supplementary material for similar evaluations of our face-decoder reconstructions from the images (F2F). As can be seen, for age and gender the classification results are highly correlated. For gender, there is an agreement of 94 % percent \% in male/female labels between the true images and our reconstructions from speech. For ethnicity, there is a good correlation on the “white” and “Asian”, but we observe less agreement on “India” and “black”. We believe this is because those classes have a smaller representation in the data (see statistics we computed on AVSpeech in Fig. 4 (b)). The performance can potentially be improved by leveraging the statistics to balance the training data for the voice encoder model, which we leave for future work.
Craniofacial attributes.
We evaluated craniofacial measurements commonly used in the literature, for capturing ratios and distances in the face [ 31 ] . For each such measurement, we computed the correlation between F2F (Fig. 5 (a)), and our corresponding S2F reconstructions (Fig. 5 (b)). Face landmarks were computed using the DEST library [ 1 ] . Note that this evaluation is made possible because we are working with normalized faces (neutral expression, frontal-facing), thus differences between the facial landmarks’ positions reflect geometric craniofacial changes. Fig. 5 (c) shows the Pearson correlation coefficient for several measures, computed over 1,000 random samples from the AVSpeech test set. As can be seen, there is statistically significant (i.e., p < 0.001 𝑝 0.001 p<0.001 ) positive correlation for several measurements. In particular, the highest correlation is measured for the nasal index (0.38) and nose width (0.35), the features indicative of nose structures that may affect a speaker’s voice.
| Length | cos (deg) | ||
|---|---|---|---|
| 3 seconds | |||
| 6 seconds |

Feature similarity.
We test how well a person can be recognized from on the face features predicted from speech. We first directly measure the cosine distance between our predicted features and the true ones obtained from the original face image of the speaker. Table 2 shows the average error over 5,000 test images, for the predictions using 3s and 6s audio segments. The use of longer audio clips exhibits consistent improvement in all error metrics; this further evidences the qualitative improvement we observe in Fig. 6 .
| Duration | Metric | ||||
|---|---|---|---|---|---|
| 3 sec | 5.86 | 10.02 | 18.98 | 28.92 | |
| 3 sec | 6.22 | 9.92 | 18.94 | 28.70 | |
| 3 sec | cos | 8.54 | 13.64 | 24.80 | 38.54 |
| 6 sec | 8.28 | 13.66 | 24.66 | 35.84 | |
| 6 sec | 8.34 | 13.70 | 24.66 | 36.22 | |
| 6 sec | cos | 10.92 | 17.00 | 30.60 | 45.82 |
| Random | 1.00 | 2.00 | 5.00 | 10.00 | |
| S2F recon. | Retrieved top-5 results |
We further evaluated how accurately we can retrieve the true speaker from a database of face images. To do so, we take the speech of a person to predict the feature using our Speech2Face model, and query it by computing its distances to the face features of all face images in the database. We report the retrieval performance by measuring the recall at K 𝐾 K , i.e., the percentage of time the true face is retrieved within the rank of K 𝐾 K . Table 3 shows the computed recalls for varying configurations. In all cases, the cross-modal retrieval using our model shows a significant performance gain compared to the random chance. It also shows that a longer duration of the input speech noticeably improves the performance. In Fig. 7 , we show several examples of 5 nearest faces such retrieved, which demonstrate the consistent facial characteristics that are being captured by our predicted face features.
t-SNE visualization for learned feature analysis.
To gain more insights on our predicted features, we present 2-D t-SNE plots [ 49 ] of the features in the SM.
5.2 Ablation Studies
| Iteration | 300k iter. | 500k iter. | ||
| Original image | ||||
| (ref. frame) | Pixel loss | Full loss | Pixel loss | Full loss |
Comparisons with a direct pixel loss.
Fig. 8 shows qualitative comparisons between the model trained with our full loss (Eq. 1 ) and the same model trained with only an image loss, i.e., an L 1 subscript 𝐿 1 L_{1} loss between pixel values on the decoded image layer (with the decoder fixed). The model trained with the image loss results in lower facial image quality and fewer facial variations. Our loss, measured at an early layer of the face decoder, allows for better supervision and leads to faster training and higher quality results.

The effect of audio duration and batch normalization.
We tested the effect of the duration of the input audio during both the train and test stages. Specifically, we trained two models with 3- and 6-second speech segments. We found that during the training time, the audio duration has an only subtle effect on the convergence speed, without much effect on the overall loss and the quality of reconstructions (Fig. 9 ). However, we found that feeding longer speech as input at test time leads to improvement in reconstruction quality, that is, reconstructed faces capture the personal attributes better, regardless of which of the two models are used. Fig. 6 shows several qualitative comparisons, which are also consistent with the quantitative evaluations in Tables 2 and 3 .
Fig. 9 also shows the training curves w/ and w/o Batch Normalization (BN). As can be seen, without BN the reconstructed faces converge to an average face. With BN the results contain much richer facial information.

| An Asian male speaking in English (left) & Chinese (right) | An Asian girl speaking in English |

Additional observations and limitations.
In Fig. 10 , we infer faces from different speech segments of the same person, taken from different parts within the same video, and from a different video, in order to test the stability of our Speech2Face reconstruction. The reconstructed face images are consistent within and between the videos. We show more such results in the SM.
To qualitatively test the effect of language and accent, we probe the model with an Asian male example speaking the same sentence in English and Chinese (Fig. 11 (a)). While having the same reconstructed face in both cases would be ideal, the model inferred different faces based on the spoken language. However, in other examples, e.g., Fig. 11 (b), the model was able to successfully factor out the language, reconstructing a face with Asian features even though the girl was speaking in English with no apparent accent (the audio is available in the SM). In general, we observed mixed behaviors and a more thorough examination is needed to determine to which extent the model relies on language.
More generally, the ability to capture the latent attributes from speech, such as age, gender, and ethnicity, depends on several factors such as accent, spoken language, or voice pitch. Clearly, in some cases, these vocal attributes would not match the person’s appearance. Several such typical speech-face mismatch examples are shown in Fig. 12 .

5.3 Speech2cartoon
Our face images reconstructed from speech may be used for generating personalized cartoons of speakers from their voices, as shown in Fig. 13 . We use Gboard, the keyboard app available on Android phones, which is also capable of analyzing a selfie image to produce a cartoon-like version of the face [ 32 ] . As can be seen, our reconstructions capture the facial attributes well enough for the app to work. Such cartoon re-rendering of the face may be useful as a visual representation of a person during a phone or a video-conferencing call, when the person’s identity is unknown or the person prefers not to share his/her picture. Our reconstructed faces may also be used directly, to assign faces to machine-generated voices used in home devices and virtual assistants.
6 Conclusion
We have presented a novel study of face reconstruction directly from the audio recording of a person speaking. We address this problem by learning to align the feature space of speech with that of a pre-trained face decoder using millions of natural videos of people speaking. We have demonstrated that our method can predict plausible faces with the facial attributes consistent with those of real images. By reconstructing faces directly from this cross-modal feature space, we validate visually the existence of cross-modal biometric information postulated in previous studies [ 27 , 34 ] . We believe that generating faces, as opposed to predicting specific attributes, may provide a more comprehensive view of voice-face correlations and can open up new research opportunities and applications.
Acknowledgment
The authors would like to thank Suwon Shon, James Glass, Forrester Cole and Dilip Krishnan for helpful discussion. T.-H. Oh and C. Kim were supported by QCRI-CSAIL Computer Science Research Program at MIT.
- [1] One Millisecond Deformable Shape Tracking Library (DEST). https://github.com/cheind/dest .
- [2] S. Albanie, A. Nagrani, A. Vedaldi, and A. Zisserman. Emotion recognition in speech using cross-modal transfer in the wild. In ACM Multimedia Conference (MM) , 2018.
- [3] G. Andrew, R. Arora, J. Bilmes, and K. Livescu. Deep canonical correlation analysis. In International Conference on Machine Learning (ICML) , 2013.
- [4] R. Arandjelovic and A. Zisserman. Look, listen and learn. In IEEE International Conference on Computer Vision (ICCV) , 2017.
- [5] R. Arandjelovic and A. Zisserman. Objects that sound. In European Conference on Computer Vision (ECCV), Springer , 2018.
- [6] Y. Aytar, C. Vondrick, and A. Torralba. Soundnet: Learning sound representations from unlabeled video. In Advances in Neural Information Processing Systems (NIPS) , 2016.
- [7] M. H. Bahari and H. Van Hamme. Speaker age estimation and gender detection based on supervised non-negative matrix factorization. In IEEE Workshop on Biometric Measurements and Systems for Security and Medical Applications , 2011.
- [8] L. Castrejon, Y. Aytar, C. Vondrick, H. Pirsiavash, and A. Torralba. Learning aligned cross-modal representations from weakly aligned data. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016.
- [9] J. S. Chung, A. W. Senior, O. Vinyals, and A. Zisserman. Lip reading sentences in the wild. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2017.
- [10] F. Cole, D. Belanger, D. Krishnan, A. Sarna, I. Mosseri, and W. T. Freeman. Synthesizing normalized faces from facial identity features. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2017.
- [11] V. R. de Sa. Minimizing disagreement for self-supervised classification. In Proceedings of the 1993 Connectionist Models Summer School , page 300. Psychology Press, 1994.
- [12] P. B. Denes, P. Denes, and E. Pinson. The speech chain . Macmillan, 1993.
- [13] A. Duarte, F. Roldan, M. Tubau, J. Escur, S. Pascual, A. Salvador, E. Mohedano, K. McGuinness, J. Torres, and X. Giro-i-Nieto. Wav2Pix: speech-conditioned face generation using generative adversarial networks. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2019.
- [14] A. Ephrat, I. Mosseri, O. Lang, T. Dekel, K. Wilson, A. Hassidim, W. T. Freeman, and M. Rubinstein. Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. ACM Transactions on Graphics (SIGGRAPH) , 37(4):112:1–112:11, 2018.
- [15] L. face-based identity verification service. Face++. https://www.faceplusplus.com/attributes/ .
- [16] M. Feld, F. Burkhardt, and C. Müller. Automatic speaker age and gender recognition in the car for tailoring dialog and mobile services. In Interspeech , 2010.
- [17] I. D. Gebru, S. Ba, G. Evangelidis, and R. Horaud. Tracking the active speaker based on a joint audio-visual observation model. In IEEE International Conference on Computer Vision Workshops , 2015.
- [18] J. H. Hansen, K. Williams, and H. Bořil. Speaker height estimation from speech: Fusing spectral regression and statistical acoustic models. The Journal of the Acoustical Society of America , 138(2):1052–1067, 2015.
- [19] G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. CoRR , abs/1503.02531, 2015.
- [20] K. Hoover, S. Chaudhuri, C. Pantofaru, M. Slaney, and I. Sturdy. Putting a face to the voice: Fusing audio and visual signals across a video to determine speakers. CoRR , abs/1706.00079, 2017.
- [21] S. Horiguchi, N. Kanda, and K. Nagamatsu. Face-voice matching using cross-modal embeddings. In ACM Multimedia Conference (MM) , 2018.
- [22] W.-N. Hsu, Y. Zhang, and J. Glass. Unsupervised learning of disentangled and interpretable representations from sequential data. In Advances in Neural Information Processing Systems (NIPS) , 2017.
- [23] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning (ICML) , 2015.
- [24] P. J. Isola. The Discovery of perceptual structure from visual co-occurrences in space and time . PhD thesis, Massachusetts Institute of Technology, 2015.
- [25] M. Kamachi, H. Hill, K. Lander, and E. Vatikiotis-Bateson. Putting the face to the voice: Matching identity across modality. Current Biology , 13(19):1709–1714, 2003.
- [26] T. Karras, T. Aila, S. Laine, A. Herva, and J. Lehtinen. Audio-driven facial animation by joint end-to-end learning of pose and emotion. ACM Transactions on Graphics (SIGGRAPH) , 36(4):94, 2017.
- [27] C. Kim, H. V. Shin, T.-H. Oh, A. Kaspar, M. Elgharib, and W. Matusik. On learning associations of faces and voices. In Asian Conference on Computer Vision (ACCV), Springer , 2018.
- [28] D. E. King. Dlib-ml: A machine learning toolkit. Journal of Machine Learning Research (JMLR) , 10:1755–1758, 2009.
- [29] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In International Conference for Learning Representations (ICLR) , 2015.
- [30] M.-Y. Liu and O. Tuzel. Coupled generative adversarial networks. In Advances in Neural Information Processing Systems (NIPS) , 2016.
- [31] M. Merler, N. Ratha, R. S. Feris, and J. R. Smith. Diversity in faces. CoRR , abs/1901.10436, 2019.
- [32] Mini stickers for Gboard. Google Inc. https://goo.gl/hu5DsR .
- [33] A. Nagrani, S. Albanie, and A. Zisserman. Learnable PINs: Cross-modal embeddings for person identity. In European Conference on Computer Vision (ECCV), Springer , 2018.
- [34] A. Nagrani, S. Albanie, and A. Zisserman. Seeing voices and hearing faces: Cross-modal biometric matching. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2018.
- [35] A. Nagrani, J. S. Chung, and A. Zisserman. VoxCeleb: A large-scale speaker identification dataset. Interspeech , 2017.
- [36] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng. Multimodal deep learning. In International Conference on Machine Learning (ICML) , 2011.
- [37] A. Owens and A. A. Efros. Audio-visual scene analysis with self-supervised multisensory features. In European Conference on Computer Vision (ECCV), Springer , 2018.
- [38] A. Owens, P. Isola, J. H. McDermott, A. Torralba, E. H. Adelson, and W. T. Freeman. Visually indicated sounds. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016.
- [39] A. Owens, J. Wu, J. H. McDermott, W. T. Freeman, and A. Torralba. Learning sight from sound: Ambient sound provides supervision for visual learning. International Journal of Computer Vision (IJCV) , 126(10):1120–1137, 2018.
- [40] O. M. Parkhi, A. Vedaldi, and A. Zisserman. Deep face recognition. In British Machine Vision Conference (BMVC) , 2015.
- [41] N. Sadoughi and C. Busso. Speech-driven expressive talking lips with conditional sequential generative adversarial networks. CoRR , abs/1806.00154, 2018.
- [42] A. Senocak, T.-H. Oh, J. Kim, M.-H. Yang, and I. S. Kweon. Learning to localize sound source in visual scenes. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2018.
- [43] E. Shlizerman, L. Dery, H. Schoen, and I. Kemelmacher-Shlizerman. Audio to body dynamics. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2018.
- [44] S. Shon, T.-H. Oh, and J. Glass. Noise-tolerant audio-visual online person verification using an attention-based neural network fusion. CoRR , abs/1811.10813, 2018.
- [45] H. M. Smith, A. K. Dunn, T. Baguley, and P. C. Stacey. Matching novel face and voice identity using static and dynamic facial images. Attention, Perception, & Psychophysics , 78(3):868–879, 2016.
- [46] M. Solèr, J. C. Bazin, O. Wang, A. Krause, and A. Sorkine-Hornung. Suggesting sounds for images from video collections. In European Conference on Computer Vision Workshops , 2016.
- [47] S. Suwajanakorn, S. M. Seitz, and I. Kemelmacher-Shlizerman. Synthesizing Obama: Learning lip sync from audio. ACM Transactions on Graphics (SIGGRAPH) , 36(4):95, 2017.
- [48] S. L. Taylor, T. Kim, Y. Yue, M. Mahler, J. Krahe, A. G. Rodriguez, J. K. Hodgins, and I. A. Matthews. A deep learning approach for generalized speech animation. ACM Transactions on Graphics (SIGGRAPH) , 36(4):93:1–93:11, 2017.
- [49] L. van der Maaten and G. Hinton. Visualizing data using T-SNE. Journal of Machine Learning Research (JMLR) , 9(Nov):2579–2605, 2008.
- [50] Y. Wen, M. A. Ismail, W. Liu, B. Raj, and R. Singh. Disjoint mapping network for cross-modal matching of voices and faces. In International Conference on Learning Representations (ICLR) , 2019.
- [51] O. Wiles, A. S. Koepke, and A. Zisserman. X2Face: A network for controlling face generation using images, audio, and pose codes. In European Conference on Computer Vision (ECCV), Springer , 2018.
- [52] X. Yan, J. Yang, K. Sohn, and H. Lee. Attribute2image: Conditional image generation from visual attributes. In European Conference on Computer Vision (ECCV), Springer , 2016.
- [53] R. Zazo, P. S. Nidadavolu, N. Chen, J. Gonzalez-Rodriguez, and N. Dehak. Age estimation in short speech utterances based on LSTM recurrent neural networks. IEEE Access , 6:22524–22530, 2018.
- [54] H. Zhao, C. Gan, A. Rouditchenko, C. Vondrick, J. H. McDermott, and A. Torralba. The sound of pixels. In European Conference on Computer Vision (ECCV), Springer , 2018.
Speech2Face: Learning the Face Behind a Voice
Reviewed on May 30, 2019 by Antoine Théberge • https://arxiv.org/pdf/1905.09773v1.pdf
Reference : Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik. Speech2Face: Learning the Face Behind a Voice. CVPR 2019.
- Successfully recognize general physical traits such as gender, age, and ethnicity from a voice clip
Introduction
“ How much can we infer about a person’s looks from the way they speak? ”. In this paper, the authors reconstruct a “canonical” (front facing, neutral expression, uniformly lit) face from a 6 seconds voice clip using a voice encoder.

The idea is really simple: You take a pre-trained face synthetiser [1] network. You then train a voice encoder to match its last feature vector \(v_s\) with the face synthesiser \(v_f\). If the two encoders project in a similar space, the face decoder should decode similar faces.
A natural choice for a loss would be the \(L_1\) distance between the \(v_s\) and \(v_f\). However, the authors found that the training was slow and unstable. They, therefore, used the following loss:

where \(f_{dec}\) is the first layer of the face decoder and \(f_{VGG}\) the last layer of the face encoder.
The authors used the AVSpeech dataset and extracted 1 frame and a 6 seconds audio clip from each video clip. If the video clip was shorter than six seconds, they looped it. The audio clip was then turned into a spectrogram and fed to the speech encoder.
The authors tested both qualitatively and quantitatively their model on the AVSpeech and VoxCeleb dataset.
Qualitative results are available here
For quantitative results, the authors used Face++ to compare features from the original images and the reconstructed faces. The Face++ classifiers return either “male” or “female” for gender, a continuous number for age, and one of the four values, “Asian”, “black”, “India”, or “white”, for ethnicity. The corresponding confusion matrices are available below

The authors also extracted craniofacial attributes from the reconstructed F2F and S2F images that resulted in a high correlation between the two.

They also performed top-5 recognition to determine how much you could retrieve the true speaker from the reconstructed image.

Supplementary results are aailable here
Conclusions
The authors showed that they can recover physical features from a person’s speech fairly well.
The authors stress throughout the paper, including in an “Ethical Considerations” section that a person’s true identity cannot be recovered from this.
To quote the paper:
More specifically, if a set of speakers might have vocal-visual traits that are relatively uncommon in the data, then the quality of our reconstructions for such cases may degrade. For example, if a certain language does not appear in the training data, our reconstructions will not capture well the facial attributes that may be correlated with that language. Note that some of the features in our predicted faces may not even be physically connected to speech, for example, hair color or style. However, if many speakers in the training set who speak in a similar way (e.g., in the same language) also share some common visual traits (e.g., common hair color or style), then those visual traits may show up in the predictions.
A similar paper has also emerged recently from Carnegie Mellon, but in this case, the authors use GANs to generate the images.
The hacker news thread has some interesting discussions, like different physiological features like overbite, size of vocal tracts, etc. could have been predicted instead. Also, the implications of this paper in the field of sociolinguistics; to understand how the model could predict that a certain speaker has a goatee, for example.
[1]: Synthesizing Normalized Faces from Facial Identity Features , Cole et. al, 2017
- Publications
CDFG The Computational Design & Fabrication Group
Speech2face: learning the face behind a voice, publication.
Tae-Hyun Oh*, Tali Dekel*, Changil Kim*, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik (* Equally contributed)

- DOI: 10.1109/CVPR.2019.00772
- Corpus ID: 162183917
Speech2Face: Learning the Face Behind a Voice
- Tae-Hyun Oh , Tali Dekel , +4 authors W. Matusik
- Published in Computer Vision and Pattern… 23 May 2019
- Computer Science
Figures and Tables from this paper

149 Citations
Speech2talking-face: inferring and driving a face with synchronized audio-visual representation, face reconstruction from voice using generative adversarial networks, show me your face, and i'll tell you how you speak, facefilter: audio-visual speech separation using still images, generation of facial images reflecting speaker attributes and emotions based on voice input, controlled autoencoders to generate faces from voices, when hearing the voice, who will come to your mind, facetron: a multi-speaker face-to-speech model based on cross-modal latent representations, face-based voice conversion: learning the voice behind a face.
- Highly Influenced
Facetron: Multi-speaker Face-to-Speech Model based on Cross-modal Latent Representations
54 references, wav2pix: speech-conditioned face generation using generative adversarial networks, putting a face to the voice: fusing audio and visual signals across a video to determine speakers, seeing voices and hearing faces: cross-modal biometric matching, emotion recognition in speech using cross-modal transfer in the wild, on learning associations of faces and voices, face-voice matching using cross-modal embeddings, audio-driven facial animation by joint end-to-end learning of pose and emotion, audio-visual scene analysis with self-supervised multisensory features, lip reading sentences in the wild, `putting the face to the voice' matching identity across modality, related papers.
Showing 1 through 3 of 0 Related Papers

- Architecture
- Privacy policy
- Cookie Policy
Speech2Face – An AI That Can Guess What Someone Looks Like Just by Their Voice
Speech2Face is an advanced neural network developed by MIT scientists and trained to recognize certain facial features and reconstruct people’s faces just by listening to the sound of their voices.
You’ve probably already heard about AI-powered cameras that can recognize people just by analyzing their facial features, but what if there was a way for artificial intelligence to figure out what you look like just by the sound of your voice and without comparing your voice to a database? That’s exactly what a team of scientists at MIT has been working on, and the results of their work are impressive, kind of. While their neural network, named Speech2Face, can’t yet figure out the exact facial features of a human just by their voice, it certainly gets plenty of details right.

“Our model is designed to reveal statistical correlations that exist between facial features and voices of speakers in the training data,” the creators of Speech2Face said . “The training data we use is a collection of educational videos from YouTube, and does not represent equally the entire world population. Therefore, the model—as is the case with any machine learning model—is affected by this uneven distribution of data.”
You can tell a lot about a person from the way they speak alone. For example, you can most likely tell if someone is male o female, or if they are young or old, but Speech2Face goes beyond that. It can determine fairly accurately the shape of someone’s nose, cheekbones or jaw from their voice alone, because the way the nose and other bones in our faces are structured determines the way we sound.

Ethnicity is also one of the things Speech2Face can pinpoint with accuracy from listening to someone’s voice for just a few milliseconds, as people who come from the same groups tend to have similar attributes. The AI takes a variety of factors into account, and it sometimes produces impressive results, but it’s still a work in progress.
In some cases, the AI had difficulty determining what the speaker might look like. Factors such as accent, spoken language, and voice pitch caused speech-to-face gross mismatches in which gender, age, or ethnicity were completely incorrect. For example, men with a particularly high-pitched voice were often identified as female, while females with a deep voice were identified as male. Asian people speaking fluent English also looked less Asian than when speaking their native language.

“In a way, the system is a bit like your racist uncle. He feels like he can always tell a person’s race or ethnicity based on the way they speak, but he’s often wrong,” photographer Thomas Smith said about Speech2Face.
Still, despite its limitations, Speech2Face offers a look into the future of artificial intelligence technology that both impresses and terrifies most people. Imagine a future where only a few milliseconds of voice time are enough for a neural network to put together an accurate portrait. Sure, it could help identify criminals, but what’s to stop bad actors from using the same technology for nefarious purposes?
Related posts
Hot this week.
- Most Viewed

Odditycentral
Speech2Face: Learning the Face Behind a Voice

How much can we infer about a person's looks from the way they speak? In this paper, we study the task of reconstructing a facial image of a person from a short audio recording of that person speaking. We design and train a deep neural network to perform this task using millions of natural Internet/YouTube videos of people speaking. During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how–and in what manner–our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.

Tae-Hyun Oh

Changil Kim

Inbar Mosseri

William T. Freeman
Michael Rubinstein
Wojciech Matusik
Related Research
Reconstructing faces from voices, imaginary voice: face-styled diffusion model for text-to-speech, physical attribute prediction using deep residual neural networks, crossmodal voice conversion, apb2face: audio-guided face reenactment with auxiliary pose and blink signals, whose emotion matters speaker detection without prior knowledge, the criminality from face illusion.
Please sign up or login with your details
Generation Overview
AI Generator calls
AI Video Generator calls
AI Chat messages
Genius Mode messages
Genius Mode images
AD-free experience
Private images
- Includes 500 AI Image generations, 1750 AI Chat Messages, 30 AI Video generations, 60 Genius Mode Messages and 60 Genius Mode Images per month. If you go over any of these limits, you will be charged an extra $5 for that group.
- For example: if you go over 500 AI images, but stay within the limits for AI Chat and Genius Mode, you'll be charged $5 per additional 500 AI Image generations.
- Includes 100 AI Image generations and 300 AI Chat Messages. If you go over any of these limits, you will have to pay as you go.
- For example: if you go over 100 AI images, but stay within the limits for AI Chat, you'll have to reload on credits to generate more images. Choose from $5 - $1000. You'll only pay for what you use.
Out of credits
Refill your membership to continue using DeepAI
Share your generations with friends
Speech2Face: Neural Network Predicts the Face Behind a Voice
- 27 May 2019
In a paper published recently, researchers from MIT’s Computer Science & Artificial Intelligence Laboratory have proposed a method for learning a face from audio recordings of that person speaking.
The goal of the project was to investigate how much information about a person’s looks can be inferred from the way they speak. Researchers proposed a neural network architecture designed specifically to perform the task of facial reconstruction from audio.
They used natural videos of people speaking collected from Youtube and other internet sources. The proposed approach is self-supervised and researchers exploit the natural synchronization of faces and speech in videos to learn the reconstruction of a person’s face from speech segments.

In their architecture, researchers utilize facial recognition pre-trained models as well as a face decoder model which takes as an input a latent vector and outputs an image with a reconstruction.
From the videos, they extract speech-face pairs, which are fed into two branches of the architecture. The images are encoded into a latent vector using the pre-trained face recognition model, whilst the waveform is fed into a voice encoder in a form of a spectrogram, in order to utilize the power of convolutional architectures. The encoded vector from the voice encoder is fed into the face decoder to obtain the final face reconstruction.
The evaluations of the method show that it is able to predict plausible faces with consistent facial features with the ones from real images. Researchers created a page with supplementary material where sample outputs of the method can be found. The paper was accepted as a conference paper at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019.

[…] Neurohive discussed their work: “From the videos, they extract speech-face pairs, which are fed into two branches of the architecture. The images are encoded into a latent vector using … Read more »

We’re so glad you’re here. You can expect all the best TNS content to arrive Monday through Friday to keep you on top of the news and at the top of your game.
Check your inbox for a confirmation email where you can adjust your preferences and even join additional groups.
Follow TNS on your favorite social media networks.
Become a TNS follower on LinkedIn .
Check out the latest featured and trending stories while you wait for your first TNS newsletter.
MIT’s Deep Neural Network Reconstructs Faces Using Only Voice Audio

Even if we’ve never laid eyes on a certain person, the sound of their voice can relay a lot of information: whether they are male or female, old or young, or perhaps an accent indicating which nation they might hail from. While it is possible for us to haphazardly guess at someone’s facial features, it’s likely that we won’t be able to clearly piece together what someone’s face looks like based on the sound of their voice alone.
However, it’s a different matter when machines are put to the task, as researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) have discovered in developing an AI that can vividly reconstruct people’s faces with relatively impressive detail, using only short audio clips of their voices as reference.
The team explains in their preprint paper how they trained a deep neural network — a type of multilayered artificial neural network that mimics the non-linear architecture of the human brain — using millions of Internet videos featuring over 100,000 talking heads. It is from these videos that the team’s Speech2Face AI is able to “learn” the correlations between someone’s facial features and the sounds these features will most likely produce.
“There is a strong connection between speech and appearance, part of which is a direct result of the mechanics of speech production: age, gender (which affects the pitch of our voice), the shape of the mouth, facial bone structure, thin or full lips — all can affect the sound we generate,” wrote the team. “In addition, other voice-appearance correlations stem from the way in which we talk: language, accent, speed, pronunciations — such properties of speech are often shared among nationalities and cultures, which can, in turn, translate to common physical features.”
Self-Supervised Machine Learning
While there has been previous work done in predicting the associations between faces and voices, one of the big hurdles is that these approaches require humans to manually classify and label the audio input information, linking it to some particular attribute, whether it’s a facial feature, gender or age of the person. However, as one might imagine, this would be a costly and time-consuming process for human supervisors — not to mention that such an approach would limit the output of the predicted face along with a rigidly predefined set of facial attributes.
To overcome this limitation, Speech2Face uses self-supervised learning , a relatively new machine learning technique that is still considered a subset of supervised learning, but where the training data is autonomously labeled by the machine itself, by identifying and extracting the connections between various input signals, without having to model these attributes explicitly. It’s an approach that is particularly suited to situations where the AI is gathering information on its own in a dynamic and diverse environment, such as the one found on the Internet.
Besides using self-supervised learning techniques, Speech2Face has been built using VGG-Face , an existing face recognition model that has been pre-trained on a large dataset of faces. Speech2Face also has a “voice encoder” that uses a convolutional neural network (CNN) to process a spectrogram , or a visual representation of the audio information found in sound clips running between 3 to 6 seconds in length. A separately trained “face decoder” then takes that translated information to generate a predicted version of what someone’s face might look like, using AVSpeech , a dataset of millions of speech-face pairs.

Comparing results: Original video screenshot of person speaking is in the first column; second column is reconstruction from image; third column is reconstruction from audio.
As one can see, some of the outputs from the team’s experiments bear an eerie likeness to the actual person, while others are a bit off. But overall, the results are quite impressive — even in special cases where someone might speak two different languages without an accent, the system was able to predict with relative accuracy the facial structure and even the ethnicity of the speaker.
As the team points out: “Our goal is not to predict a recognizable image of the exact face, but rather to capture dominant facial traits of the person that are correlated with the input speech.” Ultimately, such technology would be useful in a variety of situations, such as in telecommunications, where a reconstructed image or caricatured avatar of the person speaking might appear on the receiving cellular device, or in video-conferencing scenarios.
Speech2Face
Image processing, speech processing, encoder decoder, research paper implementation, this repository has all the codes of my implementation of speech to face..
/https://public-media.si-cdn.com/filer/22/b3/22b3449f-8948-44b9-967c-10911b729494/ahr0cdovl3d3dy5saxzlc2npzw5jzs5jb20vaw1hz2vzl2kvmdawlzewni8wmjgvb3jpz2luywwvywktahvtyw4tdm9py2utznjvbs1mywnl.jpeg "speech 2 face")
Requirements
- Python 3.5 or above
- keras_vggface
How much can we infer about a person’s looks from the way they speak? In this paper, we study the task of reconstructing a facial image of a person from a short audio recording of that person speaking. We design and train a deep neural network to perform this task using millions of natural Internet/YouTube videos of people speaking. During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how—and in what manner—our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers
I have Implemented it in both Pytorch and tensorflow.
The dataset used in this project is Voxceleb1 VoxCeleb is an audio-visual dataset consisting of short clips of human speech, extracted from interview videos uploaded to YouTube. The dataset consists of two versions, VoxCeleb1 and VoxCeleb2. Each version has it’s own train/test split. For each we provide YouTube URLs, face detections and tracks, audio files, cropped face videos and speaker meta-data. There is no overlap between the two versions.

Preprocessing
First audio processing,We use up to 6 seconds of audio taken extracted from youtube. If the audio clip is shorter than 6 seconds, we repeat the audio such that it becomes at least 6-seconds long. The audio waveform is resampled at 16 kHz and only a single channel is used. Spectrograms are computed by taking STFT with a Hann window of 25 mm, the hop length of 10 ms, and 512 FFT frequency bands. Each complex spectrogram S subsequently goes through the power-law compression, resulting sgn(S)|S|0.3 for real and imaginary independently, where sgn(·) denotes the signum.
We run the CNN-based face detector from Dlib , crop the face regions from the frames, and resize them to 224 × 224 pixels .The VGG-Face features are computed from the resized face images. The computed spectrogram and VGG-Face feature of each segment are collected and used for training.
Face Encoder Model
Our voice encoder module is a convolutional neural network that turns the spectrogram of a short input speech into a pseudo face feature, which is subsequently fed into the face decoder to reconstruct the face image (Fig. 2). The architecture of the voice encoder is summarized in Table 1. The blocks of a convolution layer, ReLU,and batch normalization [23] alternate with max-pooling layers, which pool along only the temporal dimension of the spectrograms, while leaving the frequency information carried over. This is intended to preserve more of the vocal characteristics, since they are better contained in the frequency content, whereas linguistic information usually spans longer time duration . At the end of these blocks, we apply average pooling along the temporal dimension. This allows us to efficiently aggregate information over time and makes the model applicable to input speech of varying duration. The pooled features are then fed into two fully-connected layers to produce a 4096-D face feature.
Loss in Encoder
A natural choice for the loss function would be the L1 distance between the features: kvf − vsk1. However, we found that the training undergoes slow and unstable progression with this loss alone. To stabilize the training, we introduce additional loss terms. Specifically, we additionally penalize the difference in the activationof the last layer of the face encoder, fVGG : R4096 → R2622,i.e., fc8 of VGG-Face, and that of the first layer of the face decoder, fdec : R 4096→R 1000, which are pre-trained and fixed during training the voice encoder. We feed both our predictions and the ground truth face features to these layers to calculate the losses.
Face Decoder
It is based on coles Method.We could have mapped from F to an output image directly using a deep network. This would need to simultaneously model variation in the geometry and textures of faces. As with Lanitis et al. [7], we have found it substantially more effective to separately generate landmarks L and textures T and render the final result using warping. We generate L using a shallow multi-layer perceptron with ReLU non-linearities applied to F. To generate the texture images, we use a deep CNN. We first use a fullyconnected layer to map from F to 14 × 14 × 256 localized features. Then, we use a set of stacked transposed convolutions [28], separated by ReLUs, with a kernel width of 5 and stride of 2 to upsample to 224 × 224 × 32 localized features. The number of channels after the i th transposed convolution is max(256/2 i , 32). Finally, we apply a 1 × 1 convolution to yield 224 × 224 × 3 RGB values. Because we are generating registered texture images, it is not unreasonable to use a fully-connected network, rather than a deep CNN. This maps from F to 224 × 224 × 3 pixel values directly using a linear transformation. Despite the spatial tiling of the CNN, these models have roughly the same number of parameters. We contrast the outputs of these approaches.
Loss in decoder
Each dashed line connects two terms that are compared in the loss function. Textures are compared using mean absolute error, landmarks using mean squared error, and FaceNet embedding using negative cosine similarity
Differential Image Wrapping
Let I0 be a 2-D image. Let L = {(x1, y1), . . . ,(xn, yn)} be a set of 2-D landmark points and let D = {(dx1, dy1), . . . ,(dxn, dyn)} be a set of displacement vectors for each control point. In the morphable model, I0 is the texture image T and D = L − L¯ is the displacement of the landmarks from the mean geometry.
The interpolation is done independently for horizontal and vertical displacements. For each dimension, we have a scalar gp defined at each 2-D control point p in L and seek to produce a dense 2-D grid of scalar values. Besides the facial landmark points, we include extra points at the boundary of the image, where we enforce zero displacement. It is implemented in tensorflow.
My Subscriptions

‘We’ll Enter Your Mosques...’: Nitesh Rane Booked For Threatening Speech, Congress Demands Security Withdrawal
Bjp mla nitesh rane sparked controversy with his inflammatory remarks threatening muslims amid an ongoing row over seer ramgiri maharaj's remarks on prophet muhammad..

Former Union minister Narayan Rane's son, BJP MLA Nitesh Rane, sparked controversy with his inflammatory remarks in a speech in Ahmednagar. Speaking at a rally organised by the Sakal Hindu Samaj on Sunday, 1 September, Rane stated, "I will threaten you in the language you understand. If you do anything against our Ramgiri Maharaj, we will come into your mosques and pick you off one by one. Keep this in mind."
Known for his contentious statements, Rane has once again courted controversy with his provocative comments.
The rally in Yeola was held in support of seer Mahant Ramgiri Maharaj and to protest the alleged injustices faced by Hindus in Bangladesh.
Last month, the police registered cases against Ramgiri Maharaj at Yeola in Nashik and Vaijapur in Chhatrapati Sambhajinagar districts as a group of Muslims gathered outside the City Chowk police station, demanding action against Hindu religious leader Ramgiri Maharaj for his alleged objectionable remarks about Prophet Muhammad.
The FIR in Vaijapur was filed under Section 302 (uttering words with deliberate intent to wound religious feelings of any person) of the Bharatiya Nyaya Sanhita (BNS) based on a complaint lodged by a local resident, news agency PTI reported.
2 FIRs Filed Against Nitesh Rane
Two separate FIRs have been filed against Nitesh Rane under the jurisdictions of Srirampur and Topkhana police stations in Ahmednagar district for delivering provocative speeches. The Topkhana police have registered the case under various sections of the Bharatiya Nyaya Sanhita, including sections 302 and 153 as Rane is accused of inciting violence and hurting religious sentiments. The police have issued a notice to Rane, summoning him for questioning.
Congress Delegation Seeks Action
In response to Rane's remarks, a Congress delegation met Mumbai Police Commissioner Vivek Phansalkar, urging action against the MLA for his provocative speeches.
#WATCH | Congress leader Varsha Gaikwad says, "Leaders who are giving provocative statements their police protection should be removed. They are trying to disturb the communal harmony of Maharashtra...The unity of Maharashtra is the identity of Maharashtra..." https://t.co/l5F0de3lKL pic.twitter.com/B0wOxH03CR — ANI (@ANI) September 2, 2024
Congress leader Varsha Gaikwad stated, "Leaders who are giving provocative statements should have their police protection removed. They are trying to disturb the communal harmony of Maharashtra. The unity of Maharashtra is the identity of Maharashtra."
NCP-SP MP Supriya Sule also commented on the issue stating that the BJP and Devendra Fadnavis, the Home Minister of Maharashtra are accountable for this matter and should be questioned about the same
ALSO READ | PM Modi’s Apology ‘Smacked Of Arrogance’: Uddhav Thackeray As MVA Rallies Against Shivaji Statue Collapse
AIMIM Question If Nitesh Rane Will Face Arrest
AIMIM national spokesperson Waris Pathan has condemned Rane’s remarks. On X (formerly Twitter), Pathan criticised Rane, saying, "BJP is trying to create communal violence before the elections in Maharashtra and is spreading hatred against Muslims through its people. In Maharashtra's Ahmednagar, BJP MLA Nitesh Rane is openly threatening that Muslims will be targeted in their mosques. His entire speech spreads hatred against Muslims. This is incitement and hate speech."
bjp महाराष्ट्र में चुनाव के पहले सांप्रदायिक हिंसा कराने की कोशिश कर रही है अपने लोगों के ज़रिए मुसलमानों के ख़िलाफ़ नफ़रत फैला रही है। मुसलमानों को खुले आम धमकियाँ दी जा रही है मस्जिद में घुस के चुन चुन के मारेंगे ऐसा खुले मंच से कहा जा रहा है। सरकार इन भड़काऊ भाषण देने… pic.twitter.com/BPKMQEX4uT — Waris Pathan (@warispathan) September 2, 2024
Pathan further questioned, "While two FIRs have already been filed against Rane for his provocative speeches, when will he be arrested? Or will he be left unchallenged like Ramgiri?"
इस भड़काऊ भाषण देने पर नीतीश राने के ख़िलाफ़ अब तक २ FIR दर्ज हो चुकी है। @CMOMaharashtra @DGPMaharashtra इसको हिरासत में कब लिया जाएगा ?? या रामगिरि की तरह इसे भी छोड़ दिया जाएगा ??? https://t.co/ON6s3aYA5K — Waris Pathan (@warispathan) September 2, 2024
Meanwhile, the ruling Mahayuti leaders are yet to comment on the row.
Top Headlines

Trending News

Trending Opinion

Personal Corner

Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications You must be signed in to change notification settings
Speech-Conditioned Face Generation with Deep Adversarial Networks
imatge-upc/speech2face
Folders and files.
| Name | Name | |||
|---|---|---|---|---|
| 17 Commits | ||||
Repository files navigation
Speech2face, important note.
Notice that this repo is a preliminary work before our Wav2Pix paper in ICASSP 2019. You probably want to check that other repo instead, as it is more mature and stable than this one.
Introduction
Image synthesis has been a trending task for the AI community in recent years. Many works have shown the potential of Generative Adversarial Networks (GANs) to deal with tasks such as text or audio to image synthesis. In particular, recent advances in deep learning using audio have inspired many works involving both visual and auditory information. In this work we propose a face synthesis method which is trained end-to-end using audio and/or language representations as inputs. We used this project as baseline.

Requirements
This implementation currently only support running with GPUs.
`python runtime.py
- type : GAN archiecture to use (gan | wgan | vanilla_gan | vanilla_wgan) . default = gan . Vanilla mean not conditional
- dataset : Dataset to use (birds | flowers) . default = flowers
- split : An integer indicating which split to use (0 : train | 1: valid | 2: test) . default = 0
- lr : The learning rate. default = 0.0002
- diter : Only for WGAN, number of iteration for discriminator for each iteration of the generator. default = 5
- vis_screen : The visdom env name for visualization. default = gan
- save_path : Path for saving the models.
- l1_coef : L1 loss coefficient in the generator loss fucntion for gan and vanilla_gan. default= 50
- l2_coef : Feature matching coefficient in the generator loss fucntion for gan and vanilla_gan. default= 100
- pre_trained_disc : Discriminator pre-tranined model path used for intializing training.
- pre_trained_gen Generator pre-tranined model path used for intializing training.
- batch_size : Batch size. default= 64
- num_workers : Number of dataloader workers used for fetching data. default = 8
- epochs : Number of training epochs. default= 200
- cls : Boolean flag to whether train with cls algorithms or not. default= False
[1] Generative Adversarial Text-to-Image Synthesis https://arxiv.org/abs/1605.05396
[2] Improved Techniques for Training GANs https://arxiv.org/abs/1606.03498
[3] Wasserstein GAN https://arxiv.org/abs/1701.07875
[4] Improved Training of Wasserstein GANs https://arxiv.org/pdf/1704.00028.pdf
- Python 100.0%
- Manage Account
- The Courier ePaper
- Evening Telegraph ePaper
- Newsletters
Person airlifted from luxury cruise ship off Fife coast
A coastguard helicopter was called to the Queen Mary 2 due to a medical emergency.

A person has been airlifted from a luxury cruise ship off the Fife coast during a medical emergency.
A coastguard helicopter was called at around 9pm on Sunday to a medical incident on board the Queen Mary 2.
The liner was passing through the Firth of Forth , close to Kinghorn, at the time the alarm was raised.
The person was evacuated by rescue teams in the water south of Elie and flight data shows they were taken by helicopter to Queen Elizabeth University Hospital in Glasgow.
The person’s condition has not been confirmed.
The Queen Mary 2 is currently carrying passengers on a 30-day cruise that started in New York last month.
The vessel was heading towards Invergordon in the Highlands at the time of the incident before it travels to ports in England, Ireland and Belgium and then heads back to the USA.
Cunard, which operates the cruise liner , has been contacted for comment.
More from Fife

Woman taken to hospital after crash closes stretch of A91 in Fife

Man facilitated transfer of £91k for crooks involved in Fife 'cold call' scam

Man, 39, hospitalised and 54-year-old charged as armed police called to Methil 'disturbance'

Flood alerts issued across Tayside, Fife and Stirling after heavy downpours

Man, 29, arrested after armed police called to Fife home

Jail for 'digital forensics' paedophile caught using VPN to access dark web in Fife

Police officer found guilty of assaulting suspect during arrest in Fife

Thunderstorms warning issued for Tayside, Fife and Stirling

Great pictures as thousands turn out for Scottish Coal Carrying Championships in Kelty

Former Dunfermline Athletic footballer Sol Bamba dies aged 39
Conversation.
Comments are currently disabled as they require cookies and it appears you've opted out of cookies on this site. To participate in the conversation, please adjust your cookie preferences in order to enable comments.

Smile 2 Poster Previews New Look at Naomi Scott Horror Sequel
By Maggie Dela Paz
Ahead of its official trailer release tomorrow, Paramount Pictures has shared a brand new Smile 2 poster for the next installment to 2022’s acclaimed supernatural horror movie. The Naomi Scott-led sequel is slated to arrive in theaters on October 18, 2024.
“About to embark on a new world tour, global pop sensation Skye Riley (Scott) begins experiencing increasingly terrifying and inexplicable events,” reads the synopsis. “Overwhelmed by the escalating horrors and the pressures of fame, Skye is forced to face her dark past to regain control of her life before it spirals out of control.”

Who’s involved in Smile 2?
Smile 2 is once again written and directed by Parker Finn. Joining Scott are Lukas Gage (Dead Boy Detectives), Dylan Gelula (Dream Scenario), Rosemarie DeWitt (Poltergeist), Raúl Castillo (Army of the Dead), Miles Gutierrez-Riley(Agatha All Along) and more. A Nightmare on Elm Street and Scream alum Kyle Gallner is also returning to reprise his role as Joel from the 2022 movie. It is produced by Finn, Marty Bowen, Wyck Godfrey, Isaac Klausner, and Robert Salerno.
The first installment was written and directed by Finn based on his 2020 short film Laura Hasn’t Slept. The original film starred Sosie Bacon, Jessie T. Usher, Kyle Gallner, Caitlin Stasey, Kal Penn, and Rob Morgan. In addition to being a critical success, it was also a huge hit at the worldwide box office with a gross of over $200 million against a reported budget of $17 million.

Maggie Dela Paz has been writing about the movie and TV industry for more than four years now. Besides being a fan of coming-of-age films and shows, she also enjoys watching K-Dramas and listening to her favorite K-Pop groups. Her current TV obsessions right now are FX’s The Bear and the popular anime My Hero Academia.
Share article

IMAGES
VIDEO
COMMENTS
Face reconstructed from speech. We consider the task of reconstructing an image of a person's face from a short input audio segment of speech. We show several results of our method on VoxCeleb dataset. Our model takes only an audio waveform as input (the true faces are shown just for reference). Note that our goal is not to reconstruct an ...
Figure 5: Craniofacial feature. Craniofacial features. We measure the correlation between craniofacial features extracted from (a) face decoder reconstructions from the original image (F2F), and (b) features extracted from our corresponding Speech2Face reconstructions (S2F); the features are computed from detected facial landmarks, as described ...
This project implements a framework to convert speech to facial features as described in the CVPR 2019 paper - Speech2Face: Learning the Face Behind a Voice by MIT CSAIL group. A detailed report on results can be found here as report.pdf.
A team led by researchers from MIT's Computer Science and Artificial Intelligence Lab (CSAIL) have recently shown that it can: they've created a new system that can produce a predicted image of someone's face from hearing them talk for only five seconds. Trained on millions of YouTube clips featuring over 100,000 different speakers ...
Speech-face association learning. The associations be-tween faces and voices have been studied extensively in many scientific disciplines. In the domain of computer vi- ... [36, 3]; or to learn the correlation between speech and emotion [2]. Our goal is to learn the correlations be-tween facial traits and speech, by directly reconstructing a
Our Speech2Face pipeline, illustrated in Fig. 2, consists of two main components: 1) a voice encoder, which takes a complex spectrogram of speech as input, and predicts a low-dimensional face feature that would correspond to the associated face; and 2) a face decoder, which takes as input the face feature and produces an image of the face in a ...
During training, our model learns voice-face correlations that allow it to produce images that capture various physical attributes of the speakers such as age, gender and ethnicity. This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes ...
The idea is really simple: You take a pre-trained face synthetiser [1] network. You then train a voice encoder to match its last feature vector vs v s with the face synthesiser vf v f. If the two encoders project in a similar space, the face decoder should decode similar faces. A natural choice for a loss would be the L1 L 1 distance between ...
Voice encoder network. Our voice encoder module is a convolutional neural network that turns the spectrogram of a short input speech into a pseudo face feature, which is sub-sequently fed into the face decoder to reconstruct the face image (Fig. 2). The architecture of the voice encoder is sum-marized in Table 1.
Publications Speech2Face: Learning the Face Behind a Voice Publication. CVPR 2019 Authors. Tae-Hyun Oh*, Tali Dekel*, Changil Kim*, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik (* Equally contributed)
Speech2Face: Learning the Face Behind a Voice (Tae-Hyun Oh, Tali Dekel, Changil Kim, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik) CVPR 2019 ... speech recognition based on facial images. The project consists of 2 major models: Sound to FaceVector: converts soundwave into a facial recognition vector;
This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how--and in what manner--our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.
Speech2Face is an advanced neural network developed by MIT scientists and trained to recognize certain facial features and reconstruct people's faces just by listening to the sound of their voices.
This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how-and in what manner-our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.
From the videos, they extract speech-face pairs, which are fed into two branches of the architecture. The images are encoded into a latent vector using the pre-trained face recognition model, whilst the waveform is fed into a voice encoder in a form of a spectrogram, in order to utilize the power of convolutional architectures.
Duarte et al. [31] proposed an end-to-end speech-to-face GAN model called Wav2Pix, which has the ability to synthesize diverse and promising face pictures according to a raw speech signal. Oh et ...
Researchers from MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) have discovered in developing an AI that can vividly reconstruct people's faces with relatively impressive detail, using only short audio clips of their voices as reference. Jun 13th, 2019 10:48am by Kimberley Mok. Images via MIT CSAIL.
As input, it takes a speech sample computed into a spectrogram - a visual representation of sound waves. Then the system encodes it into a vector with determined facial features. A face decoder. It takes the encoded vector and reconstructs the portrait from it. The image of the face is generated in standard form (front side and neutral by ...
This is done in a self-supervised manner, by utilizing the natural co-occurrence of faces and speech in Internet videos, without the need to model attributes explicitly. We evaluate and numerically quantify how--and in what manner--our Speech2Face reconstructions, obtained directly from audio, resemble the true face images of the speakers.
There is no overlap between the two versions. Our Speech2Face pipeline, consist of two main components: 1) a voice encoder, which takes a complex spectrogram of speech as input,and predicts a low-dimensional face feature that would correspond to the associated face; and 2) a face decoder, which takes as input the face feature and produces an ...
Voice2Face generates facial and tongue animations directly from recorded speech using machine learning.Read our research paper here: https://www.ea.com/seed/...
In contrast to rule-based methods, deep learning-based approaches utilize data as the primary source to generate 3D face animations. At present, the majority of 3D face animation generation methods are based on speech-driven techniques.
AIMIM Question If Nitesh Rane Will Face Arrest. AIMIM national spokesperson Waris Pathan has condemned Rane's remarks. On X (formerly Twitter), Pathan criticised Rane, saying, "BJP is trying to create communal violence before the elections in Maharashtra and is spreading hatred against Muslims through its people.
Our Speech2Face pipeline, consist of two main components: 1) a voice encoder, which takes a complex spectrogram of speech as input,and predicts a low-dimensional face feature that would correspond to the associated face; and 2) a face decoder, which takes as input the face feature and produces an image of the face in a canonical form (frontal ...
Introduction. Image synthesis has been a trending task for the AI community in recent years. Many works have shown the potential of Generative Adversarial Networks (GANs) to deal with tasks such as text or audio to image synthesis. In particular, recent advances in deep learning using audio have inspired many works involving both visual and ...
A coastguard helicopter was called to the Queen Mary 2 due to a medical emergency. ... An icon of a clock face. An icon of the an X shape. ... An icon of a speech bubble, denoting user comments.
A spectator was also killed at the rally in Pennsylvania, the Secret Service said. Former President Donald J. Trump said in a post online that he had been "shot with a bullet that pierced the ...
Ahead of its official trailer release tomorrow, Paramount Pictures has shared a brand new Smile 2 poster for the next installment to 2022's acclaimed supernatural horror movie. The Naomi Scott ...