Understanding regression analysis: overview and key uses
Last updated
22 August 2024
Reviewed by
Miroslav Damyanov
Regression analysis is a fundamental statistical method that helps us predict and understand how different factors (aka independent variables) influence a specific outcome (aka dependent variable).
Imagine you're trying to predict the value of a house. Regression analysis can help you create a formula to estimate the house's value by looking at variables like the home's size and the neighborhood's average income. This method is crucial because it allows us to predict and analyze trends based on data.
While that example is straightforward, the technique can be applied to more complex situations, offering valuable insights into fields such as economics, healthcare, marketing, and more.
- 3 uses for regression analysis in business
Businesses can use regression analysis to improve nearly every aspect of their operations. When used correctly, it's a powerful tool for learning how adjusting variables can improve outcomes. Here are three applications:

1. Prediction and forecasting
Predicting future scenarios can give businesses significant advantages. No method can guarantee absolute certainty, but regression analysis offers a reliable framework for forecasting future trends based on past data. Companies can apply this method to anticipate future sales for financial planning purposes and predict inventory requirements for more efficient space and cost management. Similarly, an insurance company can employ regression analysis to predict the likelihood of claims for more accurate underwriting.
2. Identifying inefficiencies and opportunities
Regression analysis can help us understand how the relationships between different business processes affect outcomes. Its ability to model complex relationships means that regression analysis can accurately highlight variables that lead to inefficiencies, which intuition alone may not do. Regression analysis allows businesses to improve performance significantly through targeted interventions. For instance, a manufacturing plant experiencing production delays, machine downtime, or labor shortages can use regression analysis to determine the underlying causes of these issues.
3. Making data-driven decisions
Regression analysis can enhance decision-making for any situation that relies on dependent variables. For example, a company can analyze the impact of various price points on sales volume to find the best pricing strategy for its products. Understanding buying behavior factors can help segment customers into buyer personas for improved targeting and messaging.
- Types of regression models
There are several types of regression models, each suited to a particular purpose. Picking the right one is vital to getting the correct results.
Simple linear regression analysis is the simplest form of regression analysis. It examines the relationship between exactly one dependent variable and one independent variable, fitting a straight line to the data points on a graph.
Multiple regression analysis examines how two or more independent variables affect a single dependent variable. It extends simple linear regression and requires a more complex algorithm.
Multivariate linear regression is suitable for multiple dependent variables. It allows the analysis of how independent variables influence multiple outcomes.
Logistic regression is relevant when the dependent variable is categorical, such as binary outcomes (e.g., true/false or yes/no). Logistic regression estimates the probability of a category based on the independent variables.
- 6 mistakes people make with regression analysis
Ignoring key variables is a common mistake when working with regression analysis. Here are a few more pitfalls to try and avoid:
1. Overfitting the model
If a model is too complex, it can become overly powerful and lead to a problem known as overfitting. This mistake is an especially significant problem when the independent variables don't impact the dependent data, though it can happen whenever the model over-adjusts to fit all the variables. In such cases, the model starts memorizing noise rather than meaningful data. When this happens, the model’s results will fit the training data perfectly but fail to generalize to new, unseen data, rendering the model ineffective for prediction or inference.
2. Underfitting the model
A less complex model is unlikely to draw false conclusions mistakenly. However, if the model is too simplistic, it will face the opposite problem: underfitting. In this case, the model will fail to capture the underlying patterns in the data, meaning it won't perform well on either the training or new, unseen data. This lack of complexity prevents the model from making accurate predictions or drawing meaningful inferences.
3. Neglecting model validation
Model validation is how you can be sure that a model isn't overfitting or underfitting. Imagine teaching a child to read. If you always read the same book to the child, they might memorize it and recite it perfectly, making it seem like they’ve learned to read. However, if you give them a new book, they might struggle and be unable to read it.
This scenario is similar to a model that performs well on its training data but fails with new data. Model validation involves testing the model with data it hasn’t seen before. If the model performs well on this new data, it indicates having truly learned to generalize. On the other hand, if the model only performs well on the training data and poorly on new data, it has overfitted to the training data, much like the child who can only recite the memorized book.
4. Multicollinearity
Regression analysis works best when the independent variables are genuinely independent. However, sometimes, two or more variables are highly correlated. This multicollinearity can make it hard for the model to accurately determine each variable's impact.
If a model gives poor results, checking for correlated variables may reveal the issue. You can fix it by removing one or more correlated variables or using a principal component analysis (PCA) technique, which transforms the correlated variables into a set of uncorrelated components.
5. Misinterpreting coefficients
Errors are not always due to the model itself; human error is common. These mistakes often involve misinterpreting the results. For example, someone might misunderstand the units of measure and draw incorrect conclusions. Another frequent issue in scientific analysis is confusing correlation and causation. Regression analysis can only provide insights into correlation, not causation.
6. Poor data quality
The adage “garbage in, garbage out” strongly applies to regression analysis. When low-quality data is input into a model, it analyzes noise rather than meaningful patterns. Poor data quality can manifest as missing values, unrepresentative data, outliers, and measurement errors. Additionally, the model may have excluded essential variables significantly impacting the results. All these issues can distort the relationships between variables and lead to misleading results.
- What are the assumptions that must hold for regression models?
To correctly interpret the output of a regression model, the following key assumptions about the underlying data process must hold:
The relationship between variables is linear.
There must be homoscedasticity, meaning the variance of the variables and the error term must remain constant.
All explanatory variables are independent of one another.
All variables are normally distributed.
- Real-life examples of regression analysis
Let's turn our attention to examining how a few industries use the regression analysis to improve their outcomes:
Regression analysis has many applications in healthcare, but two of the most common are improving patient outcomes and optimizing resources.
Hospitals need to use resources effectively to ensure the best patient outcomes. Regression models can help forecast patient admissions, equipment and supply usage, and more. These models allow hospitals to plan and maximize their resources.
Predicting stock prices, economic trends, and financial risks benefits the finance industry. Regression analysis can help finance professionals make informed decisions about these topics.
For example, analysts often use regression analysis to assess how changes to GDP, interest rates, and unemployment rates impact stock prices. Armed with this information, they can make more informed portfolio decisions.
The banking industry also uses regression analysis. When a loan underwriter determines whether to grant a loan, regression analysis allows them to calculate the probability that a potential lender will repay the loan.
Imagine how much more effective a company's marketing efforts could be if they could predict customer behavior. Regression analysis allows them to do so with a degree of accuracy. For example, marketers can analyze how price, advertising spend, and product features (combined) influence sales. Once they've identified key sales drivers, they can adjust their strategy to maximize revenue. They may approach this analysis in stages.
For instance, if they determine that ad spend is the biggest driver, they can apply regression analysis to data specific to advertising efforts. Doing so allows them to improve the ROI of ads. The opposite may also be true. If ad spending has little to no impact on sales, something is wrong that regression analysis might help identify.
- Regression analysis tools and software
Regression analysis by hand isn't practical. The process requires large numbers and complex calculations. Computers make even the most complex regression analysis possible. Even the most complicated AI algorithms can be considered fancy regression calculations. Many tools exist to help users create these regressions.
Another programming language—while MATLAB is a commercial tool, the open-source project Octave aims to implement much of the functionality. These languages are for complex mathematical operations, including regression analysis. Its tools for computation and visualization have made it very popular in academia, engineering, and industry for calculating regression and displaying the results. MATLAB integrates with other toolboxes so developers can extend its functionality and allow for application-specific solutions.
Python is a more general programming language than the previous examples, but many libraries are available that extend its functionality. For regression analysis, packages like Scikit-Learn and StatsModels provide the computational tools necessary for the job. In contrast, packages like Pandas and Matplotlib can handle large amounts of data and display the results. Python is a simple-to-learn, easy-to-read programming language, which can give it a leg up over the more dedicated math and statistics languages.
SAS (Statistical Analysis System) is a commercial software suite for advanced analytics, multivariate analysis, business intelligence, and data management. It includes a procedure called PROC REG that allows users to efficiently perform regression analysis on their data. The software is well-known for its data-handling capabilities, extensive documentation, and technical support. These factors make it a common choice for large-scale enterprise use and industries requiring rigorous statistical analysis.
Stata is another statistical software package. It provides an integrated data analysis, management, and graphics environment. The tool includes tools for performing a range of regression analysis tasks. This tool's popularity is due to its ease of use, reproducibility, and ability to handle complex datasets intuitively. The extensive documentation helps beginners get started quickly. Stata is widely used in academic research, economics, sociology, and political science.
Most people know Excel , but you might not know that Microsoft's spreadsheet software has an add-in called Analysis ToolPak that can perform basic linear regression and visualize the results. Excel is not an excellent choice for more complex regression or very large datasets. But for those with basic needs who only want to analyze smaller datasets quickly, it's a convenient option already in many tech stacks.
SPSS (Statistical Package for the Social Sciences) is a versatile statistical analysis software widely used in social science, business, and health. It offers tools for various analyses, including regression, making it accessible to users through its user-friendly interface. SPSS enables users to manage and visualize data, perform complex analyses, and generate reports without coding. Its extensive documentation and support make it popular in academia and industry, allowing for efficient handling of large datasets and reliable results.
What is a regression analysis in simple terms?
Regression analysis is a statistical method used to estimate and quantify the relationship between a dependent variable and one or more independent variables. It helps determine the strength and direction of these relationships, allowing predictions about the dependent variable based on the independent variables and providing insights into how each independent variable impacts the dependent variable.
What are the main types of variables used in regression analysis?
Dependent variables : typically continuous (e.g., house price) or binary (e.g., yes/no outcomes).
Independent variables : can be continuous, categorical, binary, or ordinal.
What does a regression analysis tell you?
Regression analysis identifies the relationships between a dependent variable and one or more independent variables. It quantifies the strength and direction of these relationships, allowing you to predict the dependent variable based on the independent variables and understand the impact of each independent variable on the dependent variable.
Should you be using a customer insights hub?
Do you want to discover previous research faster?
Do you share your research findings with others?
Do you analyze research data?
Start for free today, add your research, and get to key insights faster
Editor’s picks
Last updated: 18 April 2023
Last updated: 27 February 2023
Last updated: 22 August 2024
Last updated: 5 February 2023
Last updated: 16 August 2024
Last updated: 9 March 2023
Last updated: 30 April 2024
Last updated: 12 December 2023
Last updated: 11 March 2024
Last updated: 4 July 2024
Last updated: 6 March 2024
Last updated: 5 March 2024
Last updated: 13 May 2024
Latest articles
Related topics, .css-je19u9{-webkit-align-items:flex-end;-webkit-box-align:flex-end;-ms-flex-align:flex-end;align-items:flex-end;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-flex-direction:row;-ms-flex-direction:row;flex-direction:row;-webkit-box-flex-wrap:wrap;-webkit-flex-wrap:wrap;-ms-flex-wrap:wrap;flex-wrap:wrap;-webkit-box-pack:center;-ms-flex-pack:center;-webkit-justify-content:center;justify-content:center;row-gap:0;text-align:center;max-width:671px;}@media (max-width: 1079px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}}@media (max-width: 799px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}} decide what to .css-1kiodld{max-height:56px;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;}@media (max-width: 1079px){.css-1kiodld{display:none;}} build next, decide what to build next, log in or sign up.
Get started for free
- Open access
- Published: 24 August 2024
Mixed effects models but not t-tests or linear regression detect progression of apathy in Parkinson’s disease over seven years in a cohort: a comparative analysis
- Anne-Marie Hanff 1 , 2 , 3 , 4 ,
- Rejko Krüger 1 , 2 , 5 ,
- Christopher McCrum 4 ,
- Christophe Ley 6 on behalf of
BMC Medical Research Methodology volume 24 , Article number: 183 ( 2024 ) Cite this article
200 Accesses
2 Altmetric
Metrics details
Introduction
While there is an interest in defining longitudinal change in people with chronic illness like Parkinson’s disease (PD), statistical analysis of longitudinal data is not straightforward for clinical researchers. Here, we aim to demonstrate how the choice of statistical method may influence research outcomes, (e.g., progression in apathy), specifically the size of longitudinal effect estimates, in a cohort.
In this retrospective longitudinal analysis of 802 people with typical Parkinson’s disease in the Luxembourg Parkinson's study, we compared the mean apathy scores at visit 1 and visit 8 by means of the paired two-sided t-test. Additionally, we analysed the relationship between the visit numbers and the apathy score using linear regression and longitudinal two-level mixed effects models.
Mixed effects models were the only method able to detect progression of apathy over time. While the effects estimated for the group comparison and the linear regression were smaller with high p -values (+ 1.016/ 7 years, p = 0.107, -0.056/ 7 years, p = 0.897, respectively), effect estimates for the mixed effects models were positive with a very small p -value, indicating a significant increase in apathy symptoms by + 2.345/ 7 years ( p < 0.001).
The inappropriate use of paired t-tests and linear regression to analyse longitudinal data can lead to underpowered analyses and an underestimation of longitudinal change. While mixed effects models are not without limitations and need to be altered to model the time sequence between the exposure and the outcome, they are worth considering for longitudinal data analyses. In case this is not possible, limitations of the analytical approach need to be discussed and taken into account in the interpretation.
Peer Review reports
In longitudinal studies: “an outcome is repeatedly measured, i.e., the outcome variable is measured in the same subject on several occasions.” [ 1 ]. When assessing the same individuals over time, the different data points are likely to be more similar to each other than measurements taken from other individuals. Consequently, the application of special statistical techniques is required, which take into account the fact that the repeated observations of each subject are correlated [ 1 ]. Parkinson’s disease (PD) is a heterogeneous neurodegenerative disorder resulting in a wide variety of motor and non-motor symptoms including apathy, defined as a disorder of motivation, characterised by reduced goal-directed behaviour and cognitive activity and blunted affect [ 2 ]. Apathy increases over time in people with PD [ 3 ]. Specifically, apathy has been associated with the progressive denervation of ascending dopaminergic pathways in PD [ 4 , 5 ] leading to dysfunctions of circuits implicated in reward-related learning [ 5 ].
T-tests are often misused to analyse changes over time [ 6 ]. Consequently, we aim to demonstrate how the choice of statistical method may influence research outcomes, specifically the size and interpretation of longitudinal effect estimates in a cohort. Thus, the findings are intended for illustrative and educational purposes related to the statistical methodology. In a retrospective analysis of data from the Luxembourg Parkinson's study, a nation-wide, monocentric, observational, longitudinal-prospective dynamic cohort [ 7 , 8 ], we assess change in apathy using three different statistical approaches (paired t-test, linear regression, mixed effects model). We defined the following target estimand: In people diagnosed with PD, what is the change in the apathy score from visit 1 to visit 8? To estimate this change, we formulated the statistical hypothesis as follows:
While apathy was the dependent variable, we included the visit number as an independent variable (linear regression, mixed effects model) and as a grouping variable (paired t-test). The outcome apathy was measured by the discrete score from the Starkstein apathy scale (0 – 42, higher = worse) [ 9 ], a scale recommended by the Movement Disorders Society [ 10 ]. This data was obtained from the National Centre of Excellence in Research on Parkinson's disease (NCER-PD). The establishment of data collection standards, completion of the questionnaires at home at the participants’ convenience, mobile recruitment team for follow-up visits or standardized telephone questionnaire with a reduced assessment were part of the efforts in the primary study to address potential sources of bias [ 7 , 8 ]. Ethical approval was provided by the National Ethics Board (CNER Ref: 201,407/13). We used data from up to eight visits, which were performed annually between 2015 and 2023. Among the participants are people with typical PD and PD dementia (PDD), living mostly at home in Luxembourg and the Greater Region (geographically close areas of the surrounding countries Belgium, France, and Germany). People with atypical PD were excluded. The sample at the date of data export (2023.06.22) consisted of 802 individuals of which 269 (33.5%) were female. The average number of observations was 3.0. Fig. S1 reports the numbers of individuals at each visit while the characteristics of the participants are described in Table 1 .
As illustrated in the flow diagram (Fig. 1 ), the sample analysed from the paired t-test is highly selective: from the 802 participants at visit 1, the t-test only included 63 participants with data from visit 8. This arises from the fact that, first, we analyse the dataset from a dynamic cohort, i.e., the data at visit 1 were not collected at the same time point. Thus, 568 of the 802 participants joined the study less than eight years before, leading to only 234 participants eligible for the eighth yearly visit. Second, after excluding non-participants at visit 8 due to death ( n = 41) and other reasons ( n = 130), only 63 participants at visit 8 were left. To discuss the selective study population of a paired t-test, we compared the characteristics (age, education, age at diagnosis, apathy at visit 1) of the remaining 63 participants at visit 8 (included in the paired t-test) and the 127 non-participants at visit 8 (excluded from the paired t-test) [ 12 ].

Flow diagram of patient recruitment
The paired two-sided t-test compared the mean apathy score at visit 1 with the mean apathy score at the visit 8. We attract the reader’s attention to the fact that this implies a rather small sample size as it includes only those people with data from the first and 8th visit. The linear regression analysed the relationship between the visit number and the apathy score (using the “stats” package [ 13 ]), while we performed longitudinal two-level mixed effects models analysis with a random intercept on subject level, a random slope for visit number and the visit number as fixed effect (using the “lmer”-function of the “lme4”-package [ 14 ]). The latter two approaches use all available data from all visits while the paired t-test does not. We illustrated the analyses in plots with the function “plot_model” of the R package sjPlot [ 15 ]. We conducted data analysis using R version 3.6.3 [ 13 ] and the R syntax for all analyses is provided on the OSF project page ( https://doi.org/ https://doi.org/10.17605/OSF.IO/NF4YB ).
Panel A in Fig. 2 illustrates the means and standard deviations of apathy for all participants at each visit, while the flow-chart (Fig. S1 ) illustrates the number of participants at each stage. On average, we see lower apathy scores at visit 8 compared to visit 1 (higher score = worse). By definition, the paired t-test analyses pairs, and in this case, only participants with complete apathy scores at visit 1 and visit 8 are included, reducing the total analysed sample to 63 pairs of observations. Consequently, the t-test compares mean apathy scores in a subgroup of participants with data at both visits leading to different observations from Panel A, as illustrated and described in Panel B: the apathy score has increased at visit 8, hence symptoms of apathy have worsened. The outcome of the t-test along with the code is given in Table 2 . Interestingly, the effect estimates for the increase in apathy were not statistically significant (+ 1.016 points, 95%CI: -0.225, 2.257, p = 0.107). A possible reason for this non-significance is a loss of statistical power due to a small sample size included in the paired t-test. To visualise the loss of information between visit 1 and visit 8, we illustrated the complex individual trajectories of the participants in Fig. 3 . Moreover, as described in Table S1 in the supplement, the participants at visit 8 (63/190) analysed in the t-test were inherently significantly different compared to the non-participants at visit 8 (127/190): they were younger, had better education, and most importantly their apathy scores at visit 1 were lower. Consequently, those with the better overall situation kept coming back while this was not the case for those with a worse outcome at visit 1, which explains the observed (non-significant) increase. This may result in a biased estimation of change in apathy when analysed by the compared statistical methods.

Bar charts illustrating apathy scores (means and standard deviations) per visit (Panel A: all participants, Panel B: subgroup analysed in the t-test). The red line indicates the mean apathy at visit 1

Scatterplot illustrating the individual trajectories. The red line indicates the regression line
From the results in Table 2 , we see that the linear regression coefficient, representing change in apathy symptoms per year, is not significantly different from zero, indicating no change over time. One possible explanation is the violation of the assumption of independent observations for linear regressions. On the contrary, the effect estimates for the linear mixed effects models indicated a significant increase in apathy symptoms from visit 1 to visit 8 by + 2.680 points (95%CI: 1.880, 3.472, p < 0.001). Consequently, mixed effects models were the only method able to detect an increase in apathy symptoms over time and choosing mixed effect models for the analysis of longitudinal data reduces the risk of false negative results. The differences in the effect sizes are also reflected in the regression lines in Panel A and B of Fig. 4 .

Scatterplot illustrating the relationship between visit number and apathy. Apathy measured by a whole number interval scale, jitter applied on x- and y-axis to illustrate the data points (Panel A: Linear regression, Panel B: Linear mixed effects model). The red line indicates the regression line
The effect sizes differed depending on the choice of the statistical method. Thus, the paired t-test and the linear regression resulted in an output that would lead to different interpretations than the mixed effects models. More specifically, compared to the t-test and linear regression (which indicated non-significant changes in apathy of only + 1.016, -0.064 points from visit 1 to visit 8, respectively), the linear mixed effects models found an increase of + 2.680 points from visit 1 to visit 8 on the apathy scale. This increase is more than twice as high as indicated by the t-test and suggests linear mixed models is a more sensitive approach to detect meaningful changes perceived by people with PD over time.
Mixed effects models are a valuable tool in longitudinal data analysis as these models expand upon linear regression models by considering the correlation among repeated measurements within the same individuals through the estimation of a random intercept [ 1 , 16 , 17 ]. Specifically, to account for correlation between observations, linear mixed effects models use random effects to explicitly model the correlation structure, thus removing correlation from the error term. A random slope in addition to a random intercept allows both the rate of change and the mean value to vary by participant, capturing individual differences. This distinguishes them from group comparisons or standard linear regressions, in which such explicit modelling of correlation is not possible. Thus, the linear regression not considering correlation among the repeated observations leads to an underestimation of longitudinal change, explaining the smaller effect sizes and insignificant results of the regression. By including random effects, linear mixed effects models can better capture the variability within the data.
Another common challenge in longitudinal studies is missing data. Compared to the paired t-test and regression, the mixed effects models can also include participants with missing data at single visits and account for the individual trajectories of each participant as illustrated in Fig. 2 [ 18 ]. Although multiple imputation could increase the sample size, those results need to be interpreted with caution in case the data is not missing at random [ 18 , 19 ]. Note that we do not further elaborate here on this topic since this is a separate issue to statistical method comparison. Finally, assumptions of the different statistical methods need to be respected. The paired t-test assumes a normal distribution, homogeneity of variance and pairs of the same individuals in both groups [ 20 , 21 ]. While mixed effects models don’t rely on independent observations as it is the case for linear regression, all other assumptions for standard linear regression analysis (e.g., linearity, homoscedasticity, no multicollinearity) also hold for mixed effects model analyses. Thus, additional steps, e.g., check for linearity of the relationships or data transformations are required before the analysis of clinical research questions [ 17 ].
While mixed effects models are not without limitations and need to be altered to model the time sequence between the exposure and the outcome [ 1 ], they are worth considering for longitudinal data analyses. Thus, assuming an increase of apathy over time [ 3 ], mixed effects models were the only method able to detect statistically significant changes in the defined estimand, i.e., the change in apathy from visit 1 to visit 8. Possible reasons are a loss of statistical power due to a small sample size included in the paired t-test and the violence of the assumption of independent observations for linear regressions. Specifically, the effects estimated for the group comparison and the linear regression were smaller with high p -values, indicating a statistically insignificant change in apathy over time. The effect estimates for the mixed effects models were positive with a very small p -value, indicating a statistically significant increase in apathy symptoms from visit 1 to visit 8 in line with clinical expectations. Mixed effects models can be used to estimate different types of longitudinal effects while an inappropriate use of paired t-tests and linear regression to analyse longitudinal data can lead to underpowered analyses and an underestimation of longitudinal change and thus clinical significance. Therefore, researchers should more often consider mixed effects models for longitudinal analyses. In case this is not possible, limitations of the analytical approach need to be discussed and taken into account in the interpretation.
Availability of data and materials
The LUXPARK database used in this study was obtained from the National Centre of Excellence in Research on Parkinson’s disease (NCER-PD). NCER-PD database are not publicly available as they are linked to the Luxembourg Parkinson’s study and its internal regulations. The NCER-PD Consortium is willing to share its available data. Its access policy was devised based on the study ethics documents, including the informed consent form approved by the national ethics committee. Requests for access to datasets should be directed to the Data and Sample Access Committee by email at [email protected].
The code is available on OSF ( https://doi.org/10.17605/OSF.IO/NF4YB )
Abbreviations
Parkinson's disease
Null hypothesis
Alternative hypothesis
Parkinson's disease dementia
National Centre of Excellence in Research on Parkinson's disease
Open Science Framework
Confidence Interval
Twisk JWR. Applied Longitudinal Data Analysis for Epidemiology. A Practical Guide: Cambridge University Press; 2013.
Book Google Scholar
Levy R, Dubois B. Apathy and the functional anatomy of the prefrontal cortex-basal ganglia circuits. Cereb Cortex. 2006;16(7):916–28.
Article PubMed Google Scholar
Poewe W, Seppi K, Tanner CM, Halliday GM, Brundin P, Volkmann J, et al. Parkinson disease. Nat Rev Dis Primers. 2017;3:17013.
Pagonabarraga J, Kulisevsky J, Strafella AP, Krack P. Apathy in Parkinson’s disease: clinical features, neural substrates, diagnosis, and treatment. Lancet Neurol. 2015;14(5):518–31.
Drui G, Carnicella S, Carcenac C, Favier M, Bertrand A, Boulet S, Savasta M. Loss of dopaminergic nigrostriatal neurons accounts for the motivational and affective deficits in Parkinson’s disease. Mol Psychiatry. 2014;19(3):358–67.
Article CAS PubMed Google Scholar
Liang G, Fu W, Wang K. Analysis of t-test misuses and SPSS operations in medical research papers. Burns Trauma. 2019;7:31.
Article PubMed PubMed Central Google Scholar
Hipp G, Vaillant M, Diederich NJ, Roomp K, Satagopam VP, Banda P, et al. The Luxembourg Parkinson’s Study: a comprehensive approach for stratification and early diagnosis. Front Aging Neurosci. 2018;10:326.
Pavelka L, Rawal R, Ghosh S, Pauly C, Pauly L, Hanff A-M, et al. Luxembourg Parkinson’s study -comprehensive baseline analysis of Parkinson’s disease and atypical parkinsonism. Front Neurol. 2023;14:1330321.
Starkstein SE, Mayberg HS, Preziosi TJ, Andrezejewski P, Leiguarda R, Robinson RG. Reliability, validity, and clinical correlates of apathy in Parkinson’s disease. J Neuropsychiatry Clin Neurosci. 1992;4(2):134–9.
Leentjens AF, Dujardin K, Marsh L, Martinez-Martin P, Richard IH, Starkstein SE, et al. Apathy and anhedonia rating scales in Parkinson’s disease: critique and recommendations. Mov Disord. 2008;23(14):2004–14.
Goetz CG, Tilley BC, Shaftman SR, Stebbins GT, Fahn S, Martinez-Martin P, et al. Movement Disorder Society-sponsored revision of the Unified Parkinson’s Disease Rating Scale (MDS-UPDRS): scale presentation and clinimetric testing results. Mov Disord. 2008;23(15):2129–70.
Little RJA. A test of missing completely at random for multivariate data with missing values. J Am Stat Assoc. 1988;83(404):1198–202.
Article Google Scholar
R Core Team. R: A language and environment for statistical computing Vienna: R Foundation for Statistical Computing; 2023. Available from: https://www.R-project.org/ .
Bates D, Maechler M, Bolker B, Walker S. Fitting linear mixed-effects models using lme4. J Stat Softw. 2015;67:1–48.
Lüdecke D. sjPlot: Data Visualization for Statistics in Social Science. 2022 [R package version 2.8.11]. Available from: https://CRAN.R-project.org/package=sjPlot .
Twisk JWR. Applied Multilevel Analysis: A Practical Guide for Medical Researchers. Cambridge: Cambridge University Press; 2006.
Twisk JWR. Applied Mixed Model Analysis. New York: A Practical Guide; 2019.
Long DJ. Longitudinal data analysis for the behavioral sciences using R. United States of America: SAGE; 2012.
Google Scholar
Twisk JWR, de Boer M, de Vente W, Heymans M. Multiple imputation of missing values was not necessary before performing a longitudinal mixed-model analysis. J Clin Epidemiol. 2013;66(9):1022–8.
Student. The probable error of a mean. Biometrika. 1908;6(1):1–25.
Polit DF. Statistics and Data Analysis for Nursing Research. England: Pearson; 2014.
Download references
Acknowledgements
We would like to thank all participants of the Luxembourg Parkinson’s Study for their important support of our research. Furthermore, we acknowledge the joint effort of the National Centre of Excellence in Research on Parkinson’s Disease (NCER-PD) Consortium members from the partner institutions Luxembourg Centre for Systems Biomedicine, Luxembourg Institute of Health, Centre Hospitalier de Luxembourg, and Laboratoire National de Santé generally contributing to the Luxembourg Parkinson’s Study as listed below:
Geeta ACHARYA 2, Gloria AGUAYO 2, Myriam ALEXANDRE 2, Muhammad ALI 1, Wim AMMERLANN 2, Giuseppe ARENA 1, Michele BASSIS 1, Roxane BATUTU 3, Katy BEAUMONT 2, Sibylle BÉCHET 3, Guy BERCHEM 3, Alexandre BISDORFF 5, Ibrahim BOUSSAAD 1, David BOUVIER 4, Lorieza CASTILLO 2, Gessica CONTESOTTO 2, Nancy DE BREMAEKER 3, Brian DEWITT 2, Nico DIEDERICH 3, Rene DONDELINGER 5, Nancy E. RAMIA 1, Angelo Ferrari 2, Katrin FRAUENKNECHT 4, Joëlle FRITZ 2, Carlos GAMIO 2, Manon GANTENBEIN 2, Piotr GAWRON 1, Laura Georges 2, Soumyabrata GHOSH 1, Marijus GIRAITIS 2,3, Enrico GLAAB 1, Martine GOERGEN 3, Elisa GÓMEZ DE LOPE 1, Jérôme GRAAS 2, Mariella GRAZIANO 7, Valentin GROUES 1, Anne GRÜNEWALD 1, Gaël HAMMOT 2, Anne-Marie HANFF 2, 10, 11, Linda HANSEN 3, Michael HENEKA 1, Estelle HENRY 2, Margaux Henry 2, Sylvia HERBRINK 3, Sascha HERZINGER 1, Alexander HUNDT 2, Nadine JACOBY 8, Sonja JÓNSDÓTTIR 2,3, Jochen KLUCKEN 1,2,3, Olga KOFANOVA 2, Rejko KRÜGER 1,2,3, Pauline LAMBERT 2, Zied LANDOULSI 1, Roseline LENTZ 6, Laura LONGHINO 3, Ana Festas Lopes 2, Victoria LORENTZ 2, Tainá M. MARQUES 2, Guilherme MARQUES 2, Patricia MARTINS CONDE 1, Patrick MAY 1, Deborah MCINTYRE 2, Chouaib MEDIOUNI 2, Francoise MEISCH 1, Alexia MENDIBIDE 2, Myriam MENSTER 2, Maura MINELLI 2, Michel MITTELBRONN 1, 2, 4, 10, 12, 13, Saïda MTIMET 2, Maeva Munsch 2, Romain NATI 3, Ulf NEHRBASS 2, Sarah NICKELS 1, Beatrice NICOLAI 3, Jean-Paul NICOLAY 9, Fozia NOOR 2, Clarissa P. C. GOMES 1, Sinthuja PACHCHEK 1, Claire PAULY 2,3, Laure PAULY 2, 10, Lukas PAVELKA 2,3, Magali PERQUIN 2, Achilleas PEXARAS 2, Armin RAUSCHENBERGER 1, Rajesh RAWAL 1, Dheeraj REDDY BOBBILI 1, Lucie REMARK 2, Ilsé Richard 2, Olivia ROLAND 2, Kirsten ROOMP 1, Eduardo ROSALES 2, Stefano SAPIENZA 1, Venkata SATAGOPAM 1, Sabine SCHMITZ 1, Reinhard SCHNEIDER 1, Jens SCHWAMBORN 1, Raquel SEVERINO 2, Amir SHARIFY 2, Ruxandra SOARE 1, Ekaterina SOBOLEVA 1,3, Kate SOKOLOWSKA 2, Maud Theresine 2, Hermann THIEN 2, Elodie THIRY 3, Rebecca TING JIIN LOO 1, Johanna TROUET 2, Olena TSURKALENKO 2, Michel VAILLANT 2, Carlos VEGA 2, Liliana VILAS BOAS 3, Paul WILMES 1, Evi WOLLSCHEID-LENGELING 1, Gelani ZELIMKHANOV 2,3
1 Luxembourg Centre for Systems Biomedicine, University of Luxembourg, Esch-sur-Alzette, Luxembourg
2 Luxembourg Institute of Health, Strassen, Luxembourg
3 Centre Hospitalier de Luxembourg, Strassen, Luxembourg
4 Laboratoire National de Santé, Dudelange, Luxembourg
5 Centre Hospitalier Emile Mayrisch, Esch-sur-Alzette, Luxembourg
6 Parkinson Luxembourg Association, Leudelange, Luxembourg
7 Association of Physiotherapists in Parkinson's Disease Europe, Esch-sur-Alzette, Luxembourg
8 Private practice, Ettelbruck, Luxembourg
9 Private practice, Luxembourg, Luxembourg
10 Faculty of Science, Technology and Medicine, University of Luxembourg, Esch-sur-Alzette, Luxembourg
11 Department of Epidemiology, CAPHRI School for Public Health and Primary Care, Maastricht University Medical Centre+, Maastricht, the Netherlands
12 Luxembourg Center of Neuropathology, Dudelange, Luxembourg
13 Department of Life Sciences and Medicine, University of Luxembourg, Esch-sur-Alzette, Luxembourg
This work was supported by grants from the Luxembourg National Research Fund (FNR) within the National Centre of Excellence in Research on Parkinson's disease [NCERPD(FNR/NCER13/BM/11264123)]. The funding body played no role in the design of the study and collection, analysis, interpretation of data, and in writing the manuscript.
Author information
Authors and affiliations.
Transversal Translational Medicine, Luxembourg Institute of Health, Strassen, Luxembourg
Anne-Marie Hanff & Rejko Krüger
Translational Neurosciences, Luxembourg Centre for Systems Biomedicine, University of Luxembourg, Esch-Sur-Alzette, Luxembourg
Department of Epidemiology, CAPHRI Care and Public Health Research Institute, Maastricht University Medical Centre+, Maastricht, The Netherlands
Anne-Marie Hanff
Department of Nutrition and Movement Sciences, NUTRIM School of Nutrition and Translational Research in Metabolism, Maastricht University Medical Centre+, Maastricht, The Netherlands
Anne-Marie Hanff & Christopher McCrum
Parkinson Research Clinic, Centre Hospitalier du Luxembourg, Luxembourg, Luxembourg
Rejko Krüger
Department of Mathematics, University of Luxembourg, Esch-Sur-Alzette, Luxembourg
Christophe Ley
You can also search for this author in PubMed Google Scholar
- Geeta Acharya
- , Gloria Aguayo
- , Myriam Alexandre
- , Muhammad Ali
- , Wim Ammerlann
- , Giuseppe Arena
- , Michele Bassis
- , Roxane Batutu
- , Katy Beaumont
- , Sibylle Béchet
- , Guy Berchem
- , Alexandre Bisdorff
- , Ibrahim Boussaad
- , David Bouvier
- , Lorieza Castillo
- , Gessica Contesotto
- , Nancy de Bremaeker
- , Brian Dewitt
- , Nico Diederich
- , Rene Dondelinger
- , Nancy E. Ramia
- , Angelo Ferrari
- , Katrin Frauenknecht
- , Joëlle Fritz
- , Carlos Gamio
- , Manon Gantenbein
- , Piotr Gawron
- , Laura georges
- , Soumyabrata Ghosh
- , Marijus Giraitis
- , Enrico Glaab
- , Martine Goergen
- , Elisa Gómez de Lope
- , Jérôme Graas
- , Mariella Graziano
- , Valentin Groues
- , Anne Grünewald
- , Gaël Hammot
- , Anne-Marie Hanff
- , Linda Hansen
- , Michael Heneka
- , Estelle Henry
- , Margaux Henry
- , Sylvia Herbrink
- , Sascha Herzinger
- , Alexander Hundt
- , Nadine Jacoby
- , Sonja Jónsdóttir
- , Jochen Klucken
- , Olga Kofanova
- , Rejko Krüger
- , Pauline Lambert
- , Zied Landoulsi
- , Roseline Lentz
- , Laura Longhino
- , Ana Festas Lopes
- , Victoria Lorentz
- , Tainá M. Marques
- , Guilherme Marques
- , Patricia Martins Conde
- , Patrick May
- , Deborah Mcintyre
- , Chouaib Mediouni
- , Francoise Meisch
- , Alexia Mendibide
- , Myriam Menster
- , Maura Minelli
- , Michel Mittelbronn
- , Saïda Mtimet
- , Maeva Munsch
- , Romain Nati
- , Ulf Nehrbass
- , Sarah Nickels
- , Beatrice Nicolai
- , Jean-Paul Nicolay
- , Fozia Noor
- , Clarissa P. C. Gomes
- , Sinthuja Pachchek
- , Claire Pauly
- , Laure Pauly
- , Lukas Pavelka
- , Magali Perquin
- , Achilleas Pexaras
- , Armin Rauschenberger
- , Rajesh Rawal
- , Dheeraj Reddy Bobbili
- , Lucie Remark
- , Ilsé Richard
- , Olivia Roland
- , Kirsten Roomp
- , Eduardo Rosales
- , Stefano Sapienza
- , Venkata Satagopam
- , Sabine Schmitz
- , Reinhard Schneider
- , Jens Schwamborn
- , Raquel Severino
- , Amir Sharify
- , Ruxandra Soare
- , Ekaterina Soboleva
- , Kate Sokolowska
- , Maud Theresine
- , Hermann Thien
- , Elodie Thiry
- , Rebecca Ting Jiin Loo
- , Johanna Trouet
- , Olena Tsurkalenko
- , Michel Vaillant
- , Carlos Vega
- , Liliana Vilas Boas
- , Paul Wilmes
- , Evi Wollscheid-Lengeling
- & Gelani Zelimkhanov
Contributions
A-MH: Conceptualization, Methodology, Formal analysis, Investigation, Visualization, Project administration, Writing – original draft, Writing – review & editing. RK: Conceptualization, Methodology, Funding, Resources, Supervision, Project administration, Writing – review & editing. CMC: Conceptualization, Methodology, Supervision, Writing – original draft, Writing – review & editing. CL: Conceptualization, Methodology, Writing – original draft, Writing – review & editing.
Corresponding author
Correspondence to Anne-Marie Hanff .
Ethics declarations
Ethics approval and consent to participate.
The study involved human participants, was reviewed and obtained approval from the National Ethics Board Comité National d’Ethique de Recherche (CNER Ref: 201407/13). The study was performed in accordance with the Declaration of Helsinki and patients/participants provided their written informed consent to participate in this study. We confirm that we have read the Journal’s position on issues involved in ethical publication and affirm that this work is consistent with those guidelines.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary material 1., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Hanff, AM., Krüger, R., McCrum, C. et al. Mixed effects models but not t-tests or linear regression detect progression of apathy in Parkinson’s disease over seven years in a cohort: a comparative analysis. BMC Med Res Methodol 24 , 183 (2024). https://doi.org/10.1186/s12874-024-02301-7
Download citation
Received : 21 March 2024
Accepted : 01 August 2024
Published : 24 August 2024
DOI : https://doi.org/10.1186/s12874-024-02301-7
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Cohort studies
- Epidemiology
- Disease progression
- Lost to follow-up
- Statistical model
BMC Medical Research Methodology
ISSN: 1471-2288
- General enquiries: [email protected]
- Open access
- Published: 24 August 2024
Technical efficiency and its determinants in health service delivery of public health centers in East Wollega Zone, Oromia Regional State, Ethiopia: Two-stage data envelope analysis
- Edosa Tesfaye Geta 1 ,
- Dufera Rikitu Terefa 1 ,
- Adisu Tafari Shama 1 ,
- Adisu Ewunetu Desisa 1 ,
- Wase Benti Hailu 1 ,
- Wolkite Olani 1 ,
- Melese Chego Cheme 1 &
- Matiyos Lema 1
BMC Health Services Research volume 24 , Article number: 980 ( 2024 ) Cite this article
116 Accesses
Metrics details
Priority-setting becomes more difficult for decision-makers when the demand for health services and health care resources rises. Despite the fact that the Ethiopian healthcare system places a strong focus on the efficient utilization and allocation of health care resources, studies of efficiency in healthcare facilities have been very limited. Hence, the study aimed to evaluate efficiency and its determinants in public health centers.
A cross-sectional study was conducted in the East Wollega zone, Oromia Regional State, Ethiopia. Ethiopian fiscal year of 2021–2022 data was collected from August 01–30, 2022 and 34 health centers (decision-making units) were included in the analysis. Data envelope analysis was used to analyze the technical efficiency. A Tobit regression model was used to identify determinants of efficiency, declaring the statistical significance level at P < 0.05, using 95% confidence interval.
The overall efficiency score was estimated to be 0.47 (95% CI = 0.36–0.57). Out of 34 health centers, only 3 (8.82%) of them were technically efficient, with an efficiency score of 1 and 31 (91.2%) were scale-inefficient, with an average score of 0.54. A majority, 30 (88.2%) of inefficient health centers exhibited increasing return scales. The technical efficiency of urban health centers was (β = -0.35, 95% CI: -0.54, -0.07) and affected health centers’ catchment areas by armed conflicts declined (β = -0.21, 95% CI: -0.39, -0.03) by 35% and 21%, respectively. Providing in-service training for healthcare providers increased the efficiency by 27%; 95% CI, β = 0.27(0.05–0.49).
Conclusions
Only one out of ten health centers was technically efficient, indicating that nine out of ten were scale-inefficient and utilized nearly half of the healthcare resources inefficiently, despite the fact that they could potentially reduce their inputs nearly by half while still maintaining the same level of outputs. The location of health centers and armed conflict incidents significantly declined the efficiency scores, whereas in-service training improved the efficiency. Therefore, the government and health sector should work on the efficient utilization of healthcare resources, resolving armed conflicts, organizing training opportunities, and taking into account the locations of the healthcare facilities during resource allocation.
Peer Review reports
The physical relationship between resources used (inputs) and outputs is referred to as technical efficiency (TE). A technically efficient position is reached when a set of inputs yields the maximum improvement in outputs [ 1 ]. Therefore, as it serves as a tool to achieve better health, health care can be viewed as an intermediate good, and efficiency is the study of the relationship between final health outcomes (lifes saved, life years gained, or quality-adjusted life years) and resource inputs (costs in the form of labor, capital, or equipment) [ 2 ].
Efficiency is a quality of performance that is evaluated by comparing the financial worth of the inputs, the resources utilized to produce a certain output and the output itself, which is a component of the health care system. Either maximizing output for a given set of inputs or minimising inputs required to produce a given output would make a primary health care (PHC) facility efficient. Technical efficiency is the minimum amount of resources required to produce a given output. Wastage or inefficiencies occur when resources are used more than is required to produce a given level of output [ 3 ].
According to the WHO, in order to make progress towards universal health coverage (UHC), more funding for healthcare is required as well as greater value for that funding. According to the 2010 Report, 20–40% of all resources used for health care are wasted [ 4 ]. In most countries, a sizable share of total spending goes into the health sector. Therefore, decision-makers and health administrators should place a high priority on improving the efficiency of health systems [ 5 ].
Efficient utilization of healthcare resources has a significant impact on the delivery of health services. It leads to better access to health services and improves their quality by optimizing the use of resources. Healthcare systems can reduce wait times, increase the number of patients served, and enhance the overall patient experience. When resources are used efficiently, it can result in cost savings for healthcare systems, which allows for the reallocation of funds to other areas in need, potentially expanding services or investing in new technologies [ 6 ].
Also, efficient use of healthcare resources can contribute to better health outcomes. For example, proper management of medical supplies can ensure that patients receive the necessary treatments without delay, leading to improved recovery rates, and it is key to the sustainability of health services by ensuring that healthcare systems can continue to provide care without exhausting financial or material resources [ 6 , 7 ].
Furthermore, proper resource allocation can help to reduce disparities in healthcare delivery by ensuring that resources are distributed based on need so that healthcare systems can work towards providing equitable care to all populations. Efficient resource utilization contributes to the resilience of health systems, enabling them to respond effectively to emergencies, such as pandemics or natural disasters, without compromising the quality of care [ 8 ].
One of the quality dimensions emphasized in strategegy of Ethiopian health sector transformation plan (HSTP) is the theme around excellence in quality improvement and assurance, which is a component of Ethiopia's National Health Financing Strategy (2015–2035), has been providing healthcare in a way that optimizes resource utilization and minimizes wastage [ 9 ]. The majority of efficiency evaluations of Ethiopia's health system have been conducted on a worldwide scale, evaluating various nations' relative levels of efficiency.
Spending on public health nearly doubled between 1995 and 2011. One of the fastest-growing economies, the gross domestic product (GDP) increased by 9% real on average between 1999 and 2012 [ 5 ]. As a result, the whole government budget was able to triple within the same time period (at constant 2010 prices), which resulted in additional funding for health [ 10 ].
External resources also rose from 1995 to 2011 from US$6 million to US$836 million (in constant 2012 dollar) [ 11 ]. The development of the health sector, particularly primary care, was dependent on this ongoing external financing, with external funding accounting for half of primary care spending in 2011 [ 12 ]. Over the past 20 years, Ethiopia's health system has experienced exceptional growth, especially at the primary care level. Prior to 2005, hospitals and urban areas received a disproportionate share of public health spending [ 13 ].
It is becoming more and more necessary for decision-makers to manage the demand for healthcare services and the available resources while striking a balance with competing goals from other sectors. As PHC enters a new transformative phase, beginning with the Health Sector Transformation Plan (HSTP), plans call for increased resource utilization efficiency. Over the course of the subsequent five years (2015/2016–2019/2020), Ethiopia planned to achieve UHC by strengthening the implementation of the nutrition programme and expanding PHC coverage to everyone through improved access to basic curative and preventative health care services [ 9 , 14 ].
Increasing efficiency in the health sector is one way to create financial space for health, and this might potentially free up even more resources to be used for delivering high-quality healthcare [ 15 ]. While there was a considerable emphasis on more efficient resource allocation and utilization during the Health Care and Financing Strategy (1998–2015) in Ethiopia, problems with health institutions' efficient utilization of resources persisted during this time [ 10 ]. Ethiopia is one of the least efficient countries in health system in the world which was ranked 169 th out of 191 countries [ 16 ].
Although maximising health care outputs requires evaluating the technical efficiency of health facilities in providing medical care, there is the lack of studies of this kind carried out across this country. Although the primary focus of health care reforms in Ethiopia is the efficient allocation and utilization of resources within the health system, there is a lack of studies on the efficiency of the country's primary health care system that could identify contributing factors, including incidents of armed conflict within the catchment population of the healthcare facilities, that may impact the efficiency level of these health care facilities. As a result, in the current study, the factors that might have an impact on the technical efficiency of the health centers were categorized into three categories: factors related to the environment, factors related to the health care facilities, and factors related to the health care providers (Fig. 1 ).

Conceptual framework for technical efficiency of health centers in East Wollega zone, Oromia regional state, Ethiopia, 2022
In addition, the annual report of the East Wollega zonal health department for the Ethiopian fiscal year (EFY) 2021 and 2022 indicated that the performance of the health care facilities in the zone was low compared to other administrative zones of the region, Oromia Regional State. Therefore, this study aimed to evaluate technical efficiency and its determinants in the public health centers in East Wollega Zones, Oromia Regional State, Ethiopia.
Methods and materials
Study settings and design.
The study was carried out in public health care facilities, health centers found in East Wollega Zone, Oromia regional state, Ethiopia. The zone's capital city, Nekemte, is located around 330 kms from Addis Ababa, the capital of the country. The East Wollega Zone is located in the western part of the country, Ethiopia. Data for the EFY of July 2021 to June 2022 was retrospectively collected from August 1–30, 2022.
Data envelope analysis conceptual framework
A two-stage data envelope analysis (DEA) was employed in the current study. The two widely used DEA models, Banker, Charnes, and Cooper (BCC) and Charnes, Cooper, and Rhodes (CCR), were used to determine the technical efficiency (TE), pure technical efficiency (PTE), and scale efficiency (SE) scores for individual health centers which were considered as decision-making units (DMUs) in the first stage of the methodological framework. The overall technical efficiency (OTE) for the DMUs was determined using the CCR model, which assumed constant returns-to-scale (CRS), strong disposability of inputs and outputs, and convexity of the production possibility set. This efficiency value ranges from 0 to 1. Since the aim was to use the least amount of inputs with the same level of production in health centers, it is important to note that the model used input–output oriented approach. In general, this model evaluated the health centers' capabilities to produce a particular quantity of output with the least amount of inputs or, alternatively, the highest level of output that can be produced with the same amount of input. Overall, this model measured the ability of the health centers to produce a given level of output using the minimum amount of input, or alternatively, the maximum amount of output using a given amount of input, using the following formula: yrj : amount of output r from health centre j , xij : amount of input i to health centre j, ur: weight given to output; r , vi: weight given to input. i , n: number of health centers; s: number of outputs; m: number of inputs [ 17 , 18 ].
\(Max\;ho\;=\;\frac{\sum_{r=1}^suryijo}{\sum_{v=1}^mvixijo}\) |
|---|
\(Subject\ to;\) |
\(\frac{\sum_{r=1}^suryijo}{\sum_{v=1}^mvixijo}\;\leq1,j\;=\;1,\;\cdots\;jo,\;\cdots\;n,\) |
\(ur\;\geq\;0\;r\;=\;1,\;\cdots\;,s\;and\;vi\;\geq0,\;i\;=\;1\;\cdots m\) |
\(Max\;ho\;=\;\sum_{r=1}^s\text{uryrjo}.\) |
\(Subject\ to;\) |
\(Max\;ho=\sum_{r=1}^s\text{uryrjo}=1\) |
\(Max\;ho\;=\;\sum_{r=1}^suryr-\sum_{r=1}^svixij\leq\;0,\;j\;=\;1\cdots,\;n\) |
\(ur,\;vi\;\geq\;0\) |
Constant returns to scale (CRS) were measured using the CCR model. The CCR model measuresd the health centre's ability to produce the expected amount of output from a given amount of input using the formula;
\(Max\;ho\;=\;\sum_{r=1}^s\text{uryrjo}.\) |
|---|
\(Subject\;to;\) |
\(Max\;ho\;=\;\sum_{r=1}^s\text{uryrjo}=1\) |
\(Max\;ho\sum_{r=1}^suryr-\sum_{r=1}^svixij\;\leq\;0,\;j=\;1\dots,\;n\) |
\(ur,\;vi\;\geq\;0\) |
The BCC model was used to measure the variable returns to scale (VRS). When there are variations in output production levels and a proportionate increase in all inputs, this model works well for evaluating the PTE of health centers. The equation in use is:
\(Max\;ho\;=\sum_{r=1}^suryr+zjo\) |
|---|
\(Subject\;to;\) |
\(Max\;ho\;=\;\sum_{r=1}^suryr+zjo=1\) |
\(Max\;ho\;=\;\sum_{1=r}^suryr-\sum_{r=1}^svixij+zjo\leq0,\;j\;=\;1,\cdots n\) |
\(ur,\;vi\;\geq\;0\) |
In the methodological framework of the second stage, the OTE scores estimated from the first stage was regeressed using a Tobit regression model. This was to identify determinants of the technical efficiency scores of the primary health care facilities, which included factors related to health centers, health care providers, and the environment. The coefficients (β) of the independent factors indicated their direction of influence on the dependent variable, which was the OTE score. The model used has been expressed below [ 19 ].
\(Yi\ast=\;{\mathrm\beta}_0+\mathrm\beta x_i+{\mathrm\varepsilon}_{\mathrm i},\;\mathrm i=1,\;2,\;\dots\mathrm n\) |
|---|
\(Yi\ast\;=\;0,\;if\;yi\;\leq\;0,\) |
\(Yi\ast\;=\;Yi,\;if\;0\;<\;Yi\ast\;=\;1,\;if\;yi\;\geq\;1,\) |
Where γ i * is the limited dependent variable, which represented the technical efficiency score, γ i is the observed dependent (censored) variable, x i is the vector of independent variables (factors related to health centers, health care providers, and the environment). β 0 represented intercept (constant) whereas β 1 , β 2 and β 3 were the parameters of the independent variables (coefficients), ε i was a disturbance term assumed to be independently and normally distributed with zero mean and constant variance σ; and i = 1, 2,…n, (n is the number of observations, n = 34 health centers).
Study variables
Input variables.
The input variables comprised financial resources (salary and incentives) and human resources (number of administrative staffs, clinical and midwife nurses, laboratory technicians and technologists, pharmacy technicians and pharmacists, public health officers, general physicians, and other health care professionals, as well as other non-clinical staffs).
Output variables
Output variables comprised the number of women who had 4 visits of antenatal care (4ANC), number of deliveries, number of mothers who received postnatal care (PNC), number of women who had family planning visits, number of children who received full immunization, number of children aged 6–59 months who received vitamin A supplements, number of clients counseled and tested for human immunodeficiency virus (HIV), number of HIV patients who had follow-up care, number of patients diagnosed for TB, number of TB patients who had follow-up care and complete their treatment, number of outpatients who visited the health facilities for other general health services.
Depedent variable
Overall technical efficiency scores of the health centers.
Independent variables
The explanatory variables used in the Tobit regression model were the location of the health centers, accessibility of the health centers to transportation services, support from non-governmental organisations (NGOs), armed conflict incidents in the catchment areas, adequate electricity and water supply, in-service health care provider training, availability of diagnostic services (laboratory services), availability of adequate drug supply, room arrangements for proximity between related services, and marking the rooms with the number and type of services they provide.
Study health facilities
Public health centers in the districts of the East Wollega Zone were the study facilities. In the context of the Ethiopian health care system, a health center is a health facility within the primary health care system that provides promotive, preventive, curative, and rehabilitative outpatient care, including basic laboratory and pharmacy services. This health facility typically has a capacity of 10 beds for emergency and delivery services. Health centers serve as referral centers for health posts and provide supportive supervision for health extension workers (HEWs). It is expected that one health center provides services to a population of 15,000–25,000 within its designated catchment area. There were 17 districts and 67 public health centers in the zone. Nine districts (50%) and thirty-four health centers (50%) were included in the analysis.
Data collection instrument and technique
Data collection was conducted using the document review checklist, which was developed after the review of the Ethiopian standard related to the requirements for health care facilities. Data for the EFY of July 2021 to June 2022 was retrospectively collected. The contents of the document review checklist (data collection instrument) included inputs, outputs, and factors related to health centers, the environment, and health care providers.
Data analysis
Initially, STATA 14 was used to compute descriptive statistics for each input and output variable. For each input and output variable, the mean, standard deviation (SD), minimum and maximum values were presented. Next, MaxDEA7 ( http://maxdea.com ) was used to compute the technical efficiency, pure technical efficiency, scale efficiency scores, and input reduction and/or output increases.
The efficiency of the health centers below the efficiency frontier was measured in terms of their distance from the frontier. If the technical efficiency (TE) score closes to 0, it indicates that the health center is technically inefficient because its production lies below the stochastic frontier. The higher the value of the TE score, the closer the unit’s performance is to the frontier. The TE scores typically fall within the range of 0 to 1. A score of 0 usually indicates that the health care facilities (DMUs) were completely inefficient in health service delivery, whereas a score of 1 suggests that the health care facilities operated at maximum efficiency in health service delivery. In this case, the efficiency scores between these two extremes represent varying levels of the health center's performance in health service delivery. As the TE score moves from 0 to 1, it reflects the health centers’ progress toward optimal resource utilization and efficient performance of the health care facilities in health service delivery [ 20 ]. In comparison to their counterparts, health centers that implemented the best practice frontier were considered technically efficient, with an efficiency score of 1; (100% efficient), and the health centers were said to be efficient if they utilized their resources optimally, and there was no scope for increasing the outputs without increasing the amount of inputs used. The higher the score, the more efficient a health center is. Those health centers with a TE score estimated to be 1 were considered efficient, whereas those with a TE score of < 1 were considered inefficient. This means that the health centers did not utilize their resources efficiently, resulting in wastage of resources and suboptimal outputs.
In the second stage, the estimated overall technical efficiency scores obtained from the DEA were considered as the dependent variable and regressed against the set of independent variables (Fig. 1 ) namely healthcare facility-related, healthcare provider-related and environment-related factors. Finally, the statistical significance level was declared at P < 0.05 using the 95% confidence interval (CI).
Inputs used and outputs produced
A total of 34 DMUs were included in the study, and from these DMUs, input and output data were collected based on the data from July 1, 2021, to June 30, 2022 of one EFY. For the purpose of analysis, the input variables were categorized into financial resources and human resources, while maternal and child health (MCH), delivery, and general outpatient service were considered as output variables (Table 1 ).
Efficiency of the health centers
Efficient decision units in the DEA efficiency analysis model were defined relative to less efficient units, not absolute. The DMUs in our case were health centers. The estimating technique evaluated an individual health center’s efficiency by comparing its performance with a group of other efficient health centers. A health center’s efficiency reference set was the efficient health center that was used to evaluate the other health centers. The reasons behind the classification of an inefficient health centers as inefficient units were demonstrated by the efficient reference set's performance across the evaluation dimensions (Table 2 ).
Out of 34 health centers, only 3(8.82%) of them were technically efficient, and almost all 31(91.18%) were inefficient. On average, the OTE of the all 34 health centers was estimated to be 0.47, 95% CI = (0.36, 0.57). The OTE scores of the health centers varied greatly, from the lowest of 0.0003 to the highest of 1, implying that most of the health centers were using more resources to produce output than what other health centers with comparable resource levels were producing.
Scale-inefficient health centers had efficiency scores ranging from 0.0004 to 0.99. Thirty-one (91.2%) scale-inefficient health centers had an average score of 0.54; indicating that these health centers might, on average reduce 46% of their resources while maintaining the same amount of outputs. With a scale efficiency of 100%, three of the healthcare facilities (8.82%) had the highest efficiency score for their particular input–output mix.
Regarding PTE scores, 8(23.53%) of the health centers were efficient, and the average score was 0.77 ± 0.18. The return scales (RTS) of 1(2.94%), 3(8.82%), and 31(88.22%) health centers were decreasing return scales (DRS), constant return scales (CRS), and increasing return scales (IRS), respectively.
Determinants of overall technical efficiency
In this study, the Tobit regression model was used to identify the determinants of the technical efficiency of the health centers. As a dependent variable, the health facility's technical efficiency score was calculated from the DEA; Tobit regression was subsequently carried out (Table 3 ).
The location of the health centers, armed conflict incidents in the catchment areas of the health centers, and in-service training of the healthcare providers working in healthcare facicilities significantly influenced the technical efficiency scores of the health centers. Accordingly, the OTE of those health centers that were found in urban areas of the districts declined by 35%, 95% CI, β = -0.35(-0.54, -0.07) compared to the health centers found in rural areas of the districts. Similarly, the OTE of the health centers with catchment areas faced armed conflict incidents declined by 21%, 95% CI, β = -0.21 (-0.39, -0.03) compared to those health centers’ catchment areas that did not face the problem.
However, the in-service training of the health care providers who were working in the study healthcare facilities significantly improved the technical efficiency scores of the health centers. As a result, the OTE of the health centers in which their health care providers received adequate in-service training increased by 27%, 95% CI, β = 0.27 (0.05, 0.49).
The current study evaluated the technical efficiency of the health centers and identified the determinants of their efficiency. As a result, only one health center out of every 10 health centers operated efficiently, meaning that about 90% of health centers were inefficient. The average PTE score was 77%, which purely reflected the health centers’ managerial performance to organize inputs. This indicated that the health centers exhibited a 33% failure of managerial performance to organize the available health care resources. The ratio of OTE to PTE or CRS to VRS provided the SE scores. Accordingly, the majority of the DMUs, 88.22%, exhibited IRS that could expand their scale of efficiency without additional inputs, whereas only about 2% exhibited DRS that should scale down its scale of operation in order to operate at the most productive scale size (MPSS). Incontrst to this, the study conducted in China showed that more than half of the health care facilities operated at a DRS meaning that again in efficiency could be achieved only through downsizing the scale of operation in nearly 60% of the provinces [ 21 ].
In the study, the technical inefficiency of the health centers was significantly higher than the technical inefficiency findings of the study conducted in Sub-Saharan Africa countries (SSA): 65% of public health centers in Ghana [ 22 ], 59% in Pujehun district of Sierra Leone [ 23 ], 56% of public health centers in Kenya [ 24 ], and 50% of public health centers in Jimma Zone of Ethiopia [ 25 ] were technically inefficient. Similary, the systematic review study conducted in SSA showed that less than 40% of the studied health facilities were technically efficient in SSA countries [ 26 ]. These substantial discrepancies could be due to the armed conflict incidents in the catchment areas of the study health centers. This is supported by evidence that almost half of catchment areas of the studiy health centers experienced such conflicts.
The efficiency scores of the health centers varied significantly, from the lowest of 0.0003 to the highest of 1, indicating that some health centers were using more resources to produce output than other health centers with comparable amounts of resources. While only about one out of ten health centers had a scale efficiency of 100%, indicating that they had the most productive size for the particular input–output mix, in contrast to this, nine out of ten health centers were technically inefficient with 54% scale efficiency, implying they might reduce their healthcare resources almost by half while maintaining the same quantity of outputs (health services). This efficiency score was lower when compared to the efficiency score of health care facilities in Afghanstan, which showed the average efficiency score of health facilities was 0.74, when only 8.1% of the health care facilities had efficiency scores of 1(100% efficient) [ 27 ].
In the present study, the inefficiency level of health care facilities was high, which may have had an impact on the delivery of health care services. Different studies showed that the delivery of healthcare services is greatly impacted by the efficient use of healthcare resources [ 6 , 7 , 8 ]. and despite the scarcity of health care resources in the health sector, in most low- and middle-income countries (LMICs), the inefficiency of the sector persists [ 28 ].
Once more, the study identified determinants of the technical efficiency of the health centers. As a result, the efficiency score of those health centers that were located in the urban areas of the study districts declined by one-third. This finding in lines with the study conducted in SSA countries, showed that the location of health care facilities is significantly associated with the technical efficiency of the facilities [ 26 ]. Similarly, the study conducted in Europe showed that, despite performing similarly in the efficiency dimensions, a number of rural healthcare care facilities were found to be the best performers compared to urban health facilities [ 29 ]. Also, the study conducted in China revealed that the average technical efficiency of urban primary healthcare institutions fluctuated from 63.3% to 67.1%, which was lower than that of rural facilities (75.8–82.2%) from 2009 to 2019 [ 30 ].
The availability of different public and private health facilities in urban areas, such as public hospitals and private clinics, might contribute to the fact that rural health centers were significantly more efficient compared to those health centers found in the urban areas of the study districts. Patients might opt for these health facilities rather than public health centers in urban areas. In contrast to this, in rural areas, such options were not available. Again, these health facilities, the public and private health facilities might share the same catchment areas in urban areas, which could impact their health care utilization, resulting in under-utilization and lower outputs (the number of patients and clients who utilized the health services from the health facilities).
Similarly, the armed conflict incidents in the catchment areas of the health centers had a significant impact on the technical efficiency of the health centers. Accordingly, the efficiency of the health centers that of the catchment areas experienced armed conflicts declined by one-fifth compared to the health centers that of the catchment area did not experience such conflicts.
In the same way, the study conducted in Syria showed that the utilization of routine health services, such as ANC and outpatient consultations were negatively correlated with conflict incidents [ 31 ]; a study in Cameroon revealed that the population's utilization of healthcare services declined during the armed conflict [ 32 ]; a study in Nigeria showed that living in a conflict-affected area significantly decreases the likelihood of using healthcare services [ 33 ].
This could be due to the fact that healthcare providers in areas affected by violence may face many obstacles. They first encounter health system limitations: lack of medicines, medical supplies, healthcare workers, and financial resources are all consequences of conflict, which also harms health and the infrastructure that supports it. Additionally, it adds to the load already placed on health services. Second, access to communities in need of health care by both these populations and health personnel is made more challenging by armed conflict [ 33 ].
Furthermore, in-service training of the health care providers significantly improved the efficiency of the health centers. In the current study, the efficiency scores of health centers that of the health care providers had adequate in-service training increased by one-fourth compared to those health centers that of the staffs had inadequate in-service training. Similar to this, a scoping review study in LMICs revealed that combined and multidimensional training interventions could aid in enhancing the knowledge, competencies, and abilities of healthcare professionals in data administration and health care delivery [ 34 ].
Limitatations of the study
This study thoroughly evaluated the technical efficiency level of public health centers in delivering health services by using an input–output-oriented DEA model. Additionally, it pinpointed the determinants of technical efficiency in these health centers using a Tobit regression analysis. However, this technical efficiency analysis report in this study was based on the inputs and outputs data for the 2021–2022 EFY. Much might have been changed since 2021–2022 EFY. The findings aimed to bring attention to the potential advantages of this particular type of efficiency study rather than to provide blind guidance for decision-making in health care system. Due to a lack of data, the study did not include spending on drugs, non-pharmaceutical supplies, and other non-wage expenditures among the inputs. The DEA model only measures efficiency relative to best practice within the health center samples. Thus, any change in any type and number of health facilities and varibales included in the analysis can result in the different findings.
Policy implication of the study
In the current study, it was found that 90% of health centers were operating below scale efficiency, leading to the wastage of nearly half of the healthcare resources. This inefficiency likely had detrimental effects on healthcare service delivery. The findings suggest that merely allocating resources is insufficient for enhancing facility efficiency. Instead, a dual approach is necessary. This includes addressing enabling factors such as providing in-service training opportunities for healthcare providers and considering the strategic location of healthcare facilities. Simultaneously, it is imperative to mitigate disabling factors, like the incidents of armed conflicts within the catchment areas of these health care facilities. Implementing these measures at all levels could significantly improve the efficiency of health care facilities in healthcare deliveries.
Only one out of ten health centers operated with technical efficiency, indicating that approximately nine out of ten health centers used nearly half of the healthcare resources inefficiently. This is despite the fact that they could potentially reduce their inputs by nearly half while still maintaining the same level of output. The location of health centers and the armed conflict incidents in the catchment areas of the health centers significantly declined the efficiency scores of the health centers, whereas in-service training of the health care providers significantly increased the efficiency of the health centers.
Therefore, we strongly recommend the government and the health sector to focus on improving the health service delivery in the health centers by making efficient utilization of the health care resources, resolving armed conflicts with concerned bodies, organizing training opportunities for health care providers, and taking into account the rural and urban locations of the healthcare facilities when allocating resources for the healthcare facilities.
Availability of data and materials
The datasets used and/or analyzed during this study are available from the corresponding author on reasonable request.
Pa S. David JT. Definitions of efficiency. BMJ. 1999;318:1136.
Article Google Scholar
Mooney G, Russell EM, Weir RD. Choices for health care: a practical introduction to the economics of health care provision. London: Macmillian; 1986.
Book Google Scholar
Mann C, Dessie E, Adugna M, Berman P. Measuring efficiency of public health centers in Ethiopia. Harvard T.H. Boston, Massachusetts and Addis Ababa, Ethiopia: Chan School of Public Health and Federal Democratic Republic of Ethiopia Ministry of Health; 2016.
Google Scholar
World Health Organization, Yip, Winnie & Hafez, Reem. Improving health system efficiency: reforms for improving the efficiency of health systems: lessons from 10 country cases. World Health Organization; 2015. https://iris.who.int/handle/10665/185989 .
Heredia-Ortiz E. Data for efficiency: a tool for assessing health systems’ resource use efficiency. Bethesda, MD: Health Finance & Governance Project, Abt Associates Inc; 2013.
Walters JK, Sharma A, Malica E, et al. Supporting efficiency improvement in public health systems: a rapid evidence synthesis. BMC Health Serv Res. 2022;22:293. https://doi.org/10.1186/s12913-022-07694-z .
Article PubMed PubMed Central Google Scholar
Queen Elizabeth E, Jane Osareme O, Evangel Chinyere A, Opeoluwa A, Ifeoma Pamela O, Andrew ID. The impact of electronic health records on healthcare delivery and patient outcomes: a review. World J Adv Res Rev. 2023;21(2):451–60.
Bastani P, Mohammadpour M, Samadbeik M, et al. Factors influencing access and utilization of health services among older people during the COVID − 19 pandemic: a scoping review. Arch Public Health. 2021;79:190. https://doi.org/10.1186/s13690-021-00719-9 .
FMOH. Health Sector Transformation Plan (2015/16 - 2019/20). Addis Ababa, Ethiopia: Federal Democratic Republic of Ethiopia Ministry of Health; 2015.
lebachew A, Yusuf Y, Mann C, Berman P, FMOH. Ethiopia’s Progress in Health Financing and the Contribution of the 1998 Health Care and Financing Strategy in Ethiopia. Resource Tracking and Management Project. Boston and Addis Ababa: Harvard T.H. Chan School of Public Health; Breakthrough International Consultancy, PLC; and Ethiopian Federal Ministry of Health; 2015.
Alebachew A, Hatt L, Kukla M. Monitoring and Evaluating Progress towards Universal Health Coverage in Ethiopia. PLoS Med. 2014;11(9):e1001696. https://doi.org/10.1371/journal.pmed.1001696 .
Berman P, Mann C, Ricculli ML. Financing Ethiopia’s Primary Care to 2035: A Model Projecting Resource Mobilization and Costs. Boston: Harvard T.H. Chan School of Public Health; 2015.
World Bank. Ethiopia: Public Expenditure Review, Volume 1. Main Report. Public expenditure review (PER);. © Washington, DC; 2000. http://hdl.handle.net/10986/14967 . License: CC BY 3.0 IGO.
Federal Democratic Republic of Ethiopia (FDRE). Growth and Transformation Plan II (GTP II) (2015/16–2019/20). Vol. I. Addis Ababa; 2016.
Powell-Jackson T, Hanson K, McIntyre D. Fiscal space for health: a review of the literature. London, United Kingdom and Cape Town, South Africa: Working Paper 1; 2012.
Evans DB, Tandon A, Murray CJL, Lauer JA. The comparative efficiency of National of Health Systems in producing health: An analysis of 191 countries. World Health Organization. 2000;29(29):1–36. Available from: http://www.who.int/healthinfo/paper29.pdf .
Coelli TJ. A Guide to DEAP Version 2.1: a data envelopment analysis (Computer) Program. Centers for Efficiency and Productivity Analysis (CEPA) Working papers, No. 08/96.
Charnes A, Cooper WW, Seiford LM, Tone K. Data envelopment analysis: theory. Data envelopment analysis: a comprehensive text with models applications, references and DEA-solver software. 2nd ed. Dordrecht: Academic Publishers; 1994. p. 1–490.
Carson RT, Sun Y. The Tobit model with a non-zero threshold. Econometr J. 2007;10(1):1–15.
Wang D, Du K, Zhang N. Measuring technical efficiency and total factor productivity change with undesirable outputs in Stata. Stata J: Promot Commun Stat Stata. 2022;22(1):103–24.
Chai P, Zhang Y, Zhou M, et al. Technical and scale efficiency of provincial health systems in China: a bootstrapping data envelopment analysis. BMJ Open. 2019;9:e027539. https://doi.org/10.1136/bmjopen-2018-027539 .
Akazili J, Adjuik M. Using data envelopment analysis to measure the extent of technical efficiency of public health centers in Ghana. Health Hum Rights. 2008. http://www.biomedcentral.com/1472–698X/8/11.
Renner A, Kirigia JM, Zere E, Barry SP, Kirigia DG, Kamara C, et al. Technical efficiency of peripheral health units in Pujehun district of Sierra Leone: a DEA application. BMC Health Serv Res. 2005;5:77.
Kirigia JM, Emrouznejad A, Sambo LG, Munguti N, Liambila W. Using data envelopment analysis to measure the technical efficiency of public health centers in Kenya. J Med Syst. 2004;28(2):155–66.
Article PubMed Google Scholar
Bobo FT, Woldie M, Muluemebet Wordofa MA, Tsega G, Agago TA, Wolde-Michael K, Ibrahim N, Yesuf EA. Technical efficiency of public health centers in three districts in Ethiopia: two-stage data envelopment analysis. BMC Res Notes. 2018;11:465. https://doi.org/10.1186/s13104-018-3580-6 .
Tesleem KB, Indres M. Assessing the Efficiency of Health-care Facilities in Sub-Saharan Africa: A Systematic Review. Health Services Research and Managerial Epidemiology. 2020;7:1–12. https://doi.org/10.1177/2333392820919604 .
Farhad F, Khwaja S, Abo F, Said A, Mohammad Z, Sinai I, Wu Z. Efficiency analysis of primary healthcare facilities in Afghanistan. Cost Eff Res Alloc. 2022;20:24. https://doi.org/10.1186/s12962-022-00357-0 .
de Siqueira Filha NT, Li J, Phillips-Howard PA, et al. The economics of healthcare access: a scoping review on the economic impact of healthcare access for vulnerable urban populations in low- and middle-income countries. Int J Equity Health. 2022;21:191. https://doi.org/10.1186/s12939-022-01804-3 .
Javier GL, Emilio M. Rural vs urban hospital performance in a ‘competitive’ public health service. Soc Sci Med. 2010;71:1131-e1140.
Zhou J, Peng R, Chang Y, Liu Z, Gao S, Zhao C, Li Y, Feng Q, Qin X. Analyzing the efficiency of Chinese primary healthcare institutions using the Malmquist-DEA approach: evidence from urban and rural areas. Front Public Health. 2023;11:1073552. https://doi.org/10.3389/fpubh.2023.1073552 .
Abdulkarim E, Yasser AA, Hasan A, Francesco C. The impact of armed conflict on utilisation of health services in north-west Syria: an observational study. BMC Confl Health. 2021;15:91. https://doi.org/10.1186/s13031-021-00429-7 .
Eposi CH, Chia EJ, Benjamin MK. Health services utilisation before and during an armed conflict; experiences from the Southwest Region of Cameroon. Open Public Health J. 2020;13:547–54. https://doi.org/10.2174/1874944502013010547 .
Alice D. Hard to Reach: Providing Healthcare in Armed Conflict. International Peace Institute. Issue Brief; 2018. Available at: https://www.ipinst.org/2019/01/providing-healthcare-in-armed-conflict-nigeria .
Edward N, Eunice T, George B. Pre- and in-service training of health care workers on immunization data management in LMICs: a scoping review. BMC Hum Res Health. 2019;17:92. https://doi.org/10.1186/s12960-019-0437-6 .
Download references
Acknowledgements
Our special thanks go to Wollega University and study health facilities.
We received no financial supports to be disclosed.
Author information
Authors and affiliations.
School of Public Health, Institute of Health Sciences, Wollega University, Nekemte, Oromia, Ethiopia
Edosa Tesfaye Geta, Dufera Rikitu Terefa, Adisu Tafari Shama, Adisu Ewunetu Desisa, Wase Benti Hailu, Wolkite Olani, Melese Chego Cheme & Matiyos Lema
You can also search for this author in PubMed Google Scholar
Contributions
All authors participated in developing the study concept and design of the study. ET. contributed to data analysis, interpretation, report writing, manuscript preparation and acted as the corresponding author. DR, AT, A E, WB, WO, MC, and ML contributed to developing the data collection tools, data collection supervision, data entry to statistical software and report writing.
Corresponding author
Correspondence to Edosa Tesfaye Geta .
Ethics declarations
Ethics approval and consent to participate.
Wollega University's research ethical guidelines were adhered to carry out this study. The research ethics review committee (RERC) of Wollega University granted the ethical clearance number WURD-202–44/22 . A formal letter from the East Wollega Zonal Health Department was taken and given to the district health offices. The objective of the study was clearly communicated to all study health center directors and the required informed consent was obtained from all the study health centers. The study health centers’ confidentially was maintained. The codes from DMU001 to DMU034 were used in place of health facility identification in the data collection checklists. Each document of electronic and paper data was stored in a secure area. The research team was the only one with access to the data that was collected, and data sharing will be done in accordance with the ethical and legal guidelines.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/ .
Reprints and permissions
About this article
Cite this article.
Geta, E.T., Terefa, D.R., Shama, A.T. et al. Technical efficiency and its determinants in health service delivery of public health centers in East Wollega Zone, Oromia Regional State, Ethiopia: Two-stage data envelope analysis. BMC Health Serv Res 24 , 980 (2024). https://doi.org/10.1186/s12913-024-11431-z
Download citation
Received : 10 November 2023
Accepted : 12 August 2024
Published : 24 August 2024
DOI : https://doi.org/10.1186/s12913-024-11431-z
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Health centers
- Health service delivery
- Technical efficiency
BMC Health Services Research
ISSN: 1472-6963
- General enquiries: [email protected]
- Data library
New York City Rental Report: Rents Continue To Increase in July 2024

- In July 2024, the median asking rent in New York City registered at $3,421, increasing by $73, or 2.2%, compared with a year ago.
- The median asking rent for 0-2 bedrooms in the city was $3,322, reflecting an increase of $72, or 2.2%, from the previous year, while rent for 3-plus bedroom units declined by $262, or 5.0%, compared with July 2023, reaching $4,996 .
- While the median asking rent in Manhattan continued to decrease at an annual rate of 2.0%, rents in relatively affordable Brooklyn, Queens, and the Bronx continued to rise, indicating stronger demand in more affordable areas.
In July 2024, the median asking rent for all rental properties listed on Realtor.com® in New York City was $3,421. In contrast to the overall declining trend seen across the top 50 markets , the median asking rent in New York City continues to rise annually, increasing by $73, or 2.2%, compared with a year ago. Although New York City was one of the rental markets that saw the steepest rent declines during the COVID-19 pandemic, its median asking rent rebounded to pre-pandemic levels by spring 2022 and has continued to rise annually since then. As of July 2024, the median asking rent in New York City was $413, or 13.7%, higher than the same time in 2019 (pre-pandemic).
Figure 1: Rents Continue To Increase in New York City–July 2024
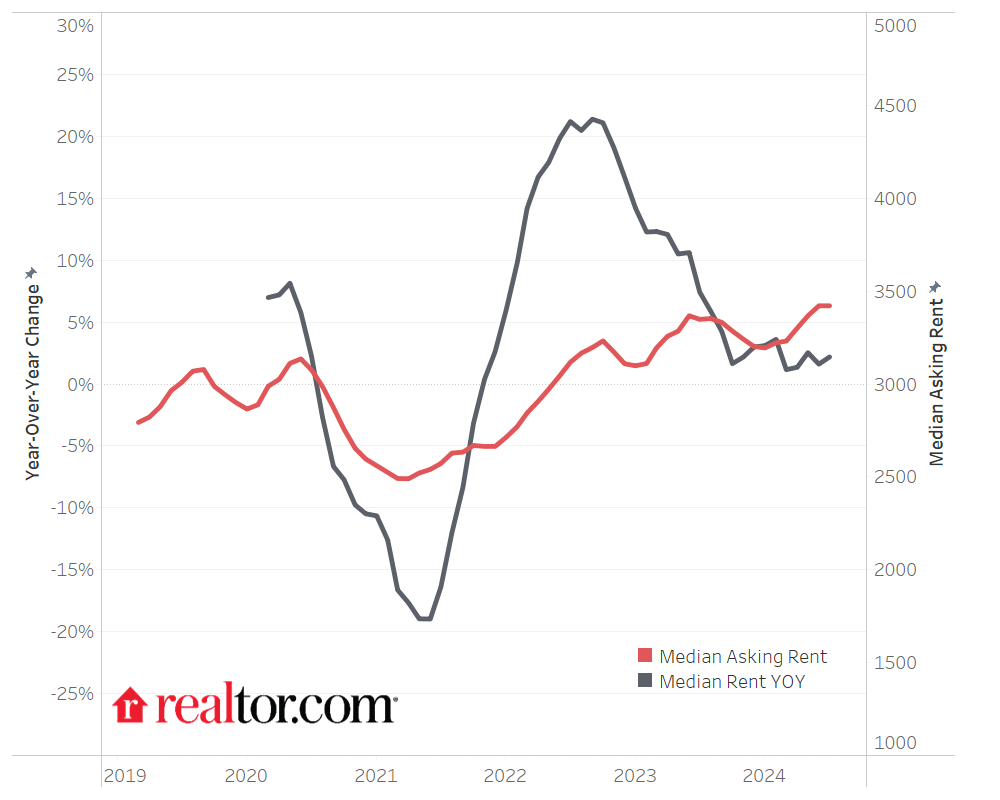
Higher demand seen in affordable smaller units
There was greater demand for smaller rental units with 0-2 bedrooms compared with those with 3 or more bedrooms in New York City. In July 2024, the median asking rent for 0-2 bedrooms in the city was $3,322, marking an increase of $72, or 2.2%, from the previous year. Meanwhile, the median asking rent among larger units with 3-plus bedrooms fell to $4,996, experiencing a year-over-year rent decline of $262, or 5.0%, compared with July 2023.
Figure 2: Rents by Unit Size in New York City–July 2024
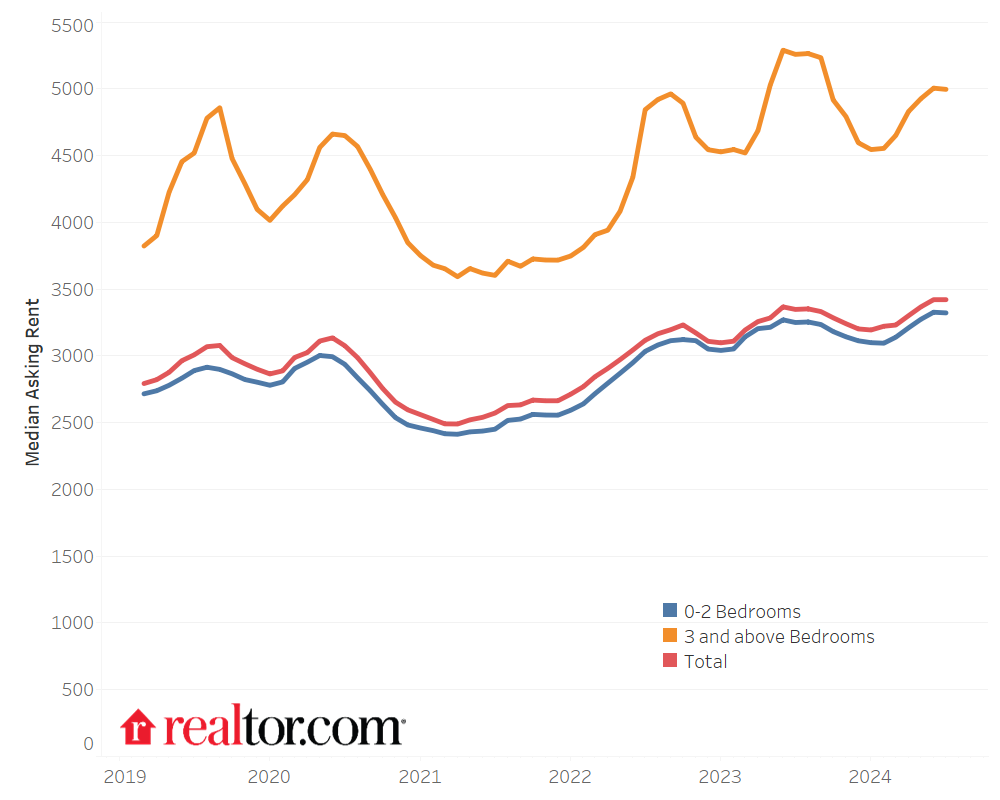
Table 1: New York City Rents by Unit Size–July 2024
| Overall | $3,421 | 2.2% | 13.7% |
| 0-2 beds | $3,322 | 2.2% | 10.6% |
| 3+ beds | $4,996 | -5.0% | 14.9% |
Higher demand seen in relatively affordable boroughs
In July 2024, the median asking rent for all rental units in Manhattan was $4,489, down $91 or 2.0% from a year ago. It was the 13th consecutive month of annual declines, and rent was $362 (-7.5%) below the peak seen in August 2019.
Additionally, in July 2024, Manhattan’s median asking rent was still $171 (-3.7%) lower than its pre-pandemic level, suggesting a relatively lower demand in this most expensive borough, perhaps indicating an ongoing willingness of workers to commute and leverage flexible working arrangements to find housing affordability, as Realtor.com previously found in the for-sale market .
In fact, to afford renting a typical home in Manhattan without spending more than 30% of income on housing (including utilities)—the standard measure of affordability—a gross household income of $14,963 per month, or $179,560 per year, is required.
Unlike the cooling rental market in Manhattan, the three relatively lower-rent boroughs of the Bronx, Brooklyn, and Queens saw rents continue to increase yearly. Among these three, Queens saw the fastest annual rental growth in July, where the median asking rent reached $3,380, up $256 or 8.2% from the same time last year. It was the highest rent level seen in our data history and was $967 (40.1%) higher than five years ago.
Meanwhile, the median asking rent in the Bronx increased by 7.7%, or $226, to $3,175 from a year ago. It was the second-highest rent level seen since March 2019 and was $1,202 (60.9%) higher than five years ago.
In Brooklyn, the median asking rent increased by 3.5%, or $124, on an annual basis, to $3,718 from a year ago. It was also the highest rent level seen in our data history and was $916 (32.7%) higher than five years ago.
To afford renting a typical home in these three boroughs while adhering to the 30% rule of thumb, the gross monthly household income required for tenants in Queens, Brooklyn, and the Bronx was $11,267, $12,393, and $10,583, respectively, or annual income of $135,200, $148,720, and $127,000 .
Figure 3: Rents by Borough in New York City–July 2024
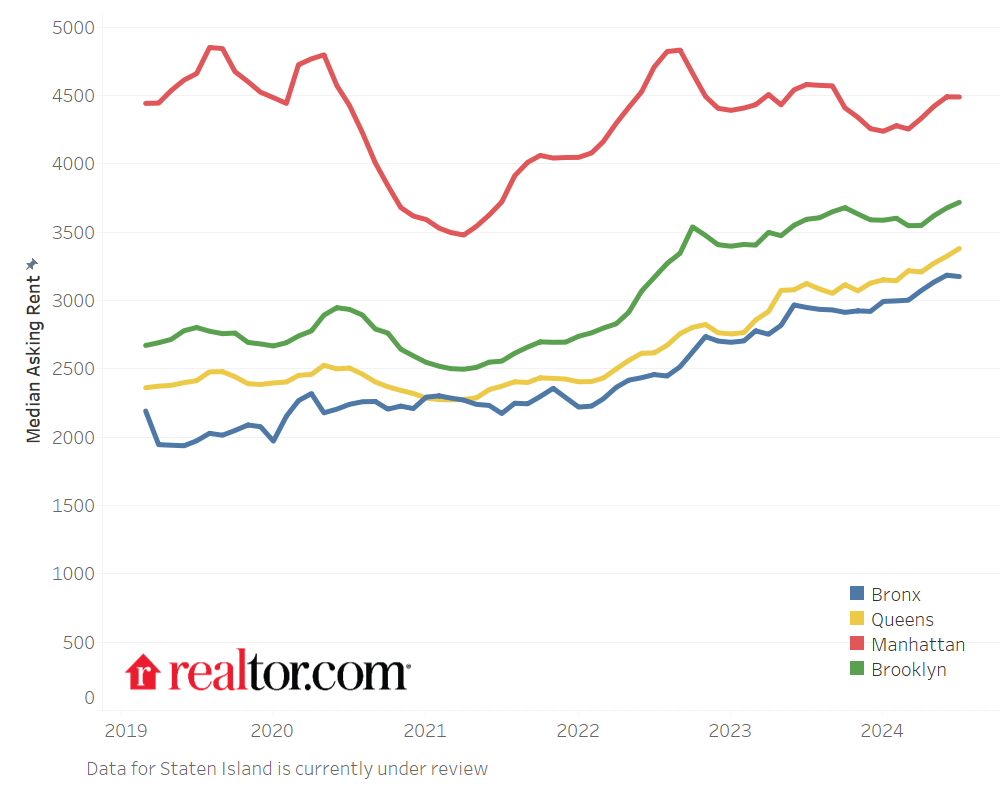
Table 2: Rents by Borough in New York City
| Manhattan | $4,489 | -2.0% | -3.7% | $179,560 |
| Brooklyn | $3,718 | 3.5% | 32.7% | $148,720 |
| Queens | $3,380 | 8.2% | 40.1% | $135,200 |
| The Bronx | $3,175 | 7.7% | 60.9% | $127,000 |
Note: Data for Staten Island is currently under review.
Methodology.
New York City rental data as of July 2024 for all units advertised as for rent on Realtor.com®. Rental units include apartments as well as private rentals (condos, townhomes, single-family homes). We use rental sources that reliably report data each month within New York City and each of its boroughs. Data for Staten Island is currently under review.
Realtor.com began publishing regular monthly rental trends reports for New York City in August 2024 with data history stretching back to March 2019.
Sign up for updates
Join our mailing list to receive the latest data and research.
arXiv's Accessibility Forum starts next month!
Help | Advanced Search
Computer Science > Computation and Language
Title: pandora's box or aladdin's lamp: a comprehensive analysis revealing the role of rag noise in large language models.
Abstract: Retrieval-Augmented Generation (RAG) has emerged as a crucial method for addressing hallucinations in large language models (LLMs). While recent research has extended RAG models to complex noisy scenarios, these explorations often confine themselves to limited noise types and presuppose that noise is inherently detrimental to LLMs, potentially deviating from real-world retrieval environments and restricting practical applicability. In this paper, we define seven distinct noise types from a linguistic perspective and establish a Noise RAG Benchmark (NoiserBench), a comprehensive evaluation framework encompassing multiple datasets and reasoning tasks. Through empirical evaluation of eight representative LLMs with diverse architectures and scales, we reveal that these noises can be further categorized into two practical groups: noise that is beneficial to LLMs (aka beneficial noise) and noise that is harmful to LLMs (aka harmful noise). While harmful noise generally impairs performance, beneficial noise may enhance several aspects of model capabilities and overall performance. Our analysis offers insights for developing more robust, adaptable RAG solutions and mitigating hallucinations across diverse retrieval scenarios.
| Subjects: | Computation and Language (cs.CL) |
| Cite as: | [cs.CL] |
| (or [cs.CL] for this version) | |
| Focus to learn more arXiv-issued DOI via DataCite (pending registration) |
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
- Privacy Policy
Home » Data Analysis – Process, Methods and Types
Data Analysis – Process, Methods and Types
Table of Contents

Data Analysis
Definition:
Data analysis refers to the process of inspecting, cleaning, transforming, and modeling data with the goal of discovering useful information, drawing conclusions, and supporting decision-making. It involves applying various statistical and computational techniques to interpret and derive insights from large datasets. The ultimate aim of data analysis is to convert raw data into actionable insights that can inform business decisions, scientific research, and other endeavors.
Data Analysis Process
The following are step-by-step guides to the data analysis process:
Define the Problem
The first step in data analysis is to clearly define the problem or question that needs to be answered. This involves identifying the purpose of the analysis, the data required, and the intended outcome.
Collect the Data
The next step is to collect the relevant data from various sources. This may involve collecting data from surveys, databases, or other sources. It is important to ensure that the data collected is accurate, complete, and relevant to the problem being analyzed.
Clean and Organize the Data
Once the data has been collected, it needs to be cleaned and organized. This involves removing any errors or inconsistencies in the data, filling in missing values, and ensuring that the data is in a format that can be easily analyzed.
Analyze the Data
The next step is to analyze the data using various statistical and analytical techniques. This may involve identifying patterns in the data, conducting statistical tests, or using machine learning algorithms to identify trends and insights.
Interpret the Results
After analyzing the data, the next step is to interpret the results. This involves drawing conclusions based on the analysis and identifying any significant findings or trends.
Communicate the Findings
Once the results have been interpreted, they need to be communicated to stakeholders. This may involve creating reports, visualizations, or presentations to effectively communicate the findings and recommendations.
Take Action
The final step in the data analysis process is to take action based on the findings. This may involve implementing new policies or procedures, making strategic decisions, or taking other actions based on the insights gained from the analysis.
Types of Data Analysis
Types of Data Analysis are as follows:
Descriptive Analysis
This type of analysis involves summarizing and describing the main characteristics of a dataset, such as the mean, median, mode, standard deviation, and range.
Inferential Analysis
This type of analysis involves making inferences about a population based on a sample. Inferential analysis can help determine whether a certain relationship or pattern observed in a sample is likely to be present in the entire population.
Diagnostic Analysis
This type of analysis involves identifying and diagnosing problems or issues within a dataset. Diagnostic analysis can help identify outliers, errors, missing data, or other anomalies in the dataset.
Predictive Analysis
This type of analysis involves using statistical models and algorithms to predict future outcomes or trends based on historical data. Predictive analysis can help businesses and organizations make informed decisions about the future.
Prescriptive Analysis
This type of analysis involves recommending a course of action based on the results of previous analyses. Prescriptive analysis can help organizations make data-driven decisions about how to optimize their operations, products, or services.
Exploratory Analysis
This type of analysis involves exploring the relationships and patterns within a dataset to identify new insights and trends. Exploratory analysis is often used in the early stages of research or data analysis to generate hypotheses and identify areas for further investigation.
Data Analysis Methods
Data Analysis Methods are as follows:
Statistical Analysis
This method involves the use of mathematical models and statistical tools to analyze and interpret data. It includes measures of central tendency, correlation analysis, regression analysis, hypothesis testing, and more.
Machine Learning
This method involves the use of algorithms to identify patterns and relationships in data. It includes supervised and unsupervised learning, classification, clustering, and predictive modeling.
Data Mining
This method involves using statistical and machine learning techniques to extract information and insights from large and complex datasets.
Text Analysis
This method involves using natural language processing (NLP) techniques to analyze and interpret text data. It includes sentiment analysis, topic modeling, and entity recognition.
Network Analysis
This method involves analyzing the relationships and connections between entities in a network, such as social networks or computer networks. It includes social network analysis and graph theory.
Time Series Analysis
This method involves analyzing data collected over time to identify patterns and trends. It includes forecasting, decomposition, and smoothing techniques.
Spatial Analysis
This method involves analyzing geographic data to identify spatial patterns and relationships. It includes spatial statistics, spatial regression, and geospatial data visualization.
Data Visualization
This method involves using graphs, charts, and other visual representations to help communicate the findings of the analysis. It includes scatter plots, bar charts, heat maps, and interactive dashboards.
Qualitative Analysis
This method involves analyzing non-numeric data such as interviews, observations, and open-ended survey responses. It includes thematic analysis, content analysis, and grounded theory.
Multi-criteria Decision Analysis
This method involves analyzing multiple criteria and objectives to support decision-making. It includes techniques such as the analytical hierarchy process, TOPSIS, and ELECTRE.
Data Analysis Tools
There are various data analysis tools available that can help with different aspects of data analysis. Below is a list of some commonly used data analysis tools:
- Microsoft Excel: A widely used spreadsheet program that allows for data organization, analysis, and visualization.
- SQL : A programming language used to manage and manipulate relational databases.
- R : An open-source programming language and software environment for statistical computing and graphics.
- Python : A general-purpose programming language that is widely used in data analysis and machine learning.
- Tableau : A data visualization software that allows for interactive and dynamic visualizations of data.
- SAS : A statistical analysis software used for data management, analysis, and reporting.
- SPSS : A statistical analysis software used for data analysis, reporting, and modeling.
- Matlab : A numerical computing software that is widely used in scientific research and engineering.
- RapidMiner : A data science platform that offers a wide range of data analysis and machine learning tools.
Applications of Data Analysis
Data analysis has numerous applications across various fields. Below are some examples of how data analysis is used in different fields:
- Business : Data analysis is used to gain insights into customer behavior, market trends, and financial performance. This includes customer segmentation, sales forecasting, and market research.
- Healthcare : Data analysis is used to identify patterns and trends in patient data, improve patient outcomes, and optimize healthcare operations. This includes clinical decision support, disease surveillance, and healthcare cost analysis.
- Education : Data analysis is used to measure student performance, evaluate teaching effectiveness, and improve educational programs. This includes assessment analytics, learning analytics, and program evaluation.
- Finance : Data analysis is used to monitor and evaluate financial performance, identify risks, and make investment decisions. This includes risk management, portfolio optimization, and fraud detection.
- Government : Data analysis is used to inform policy-making, improve public services, and enhance public safety. This includes crime analysis, disaster response planning, and social welfare program evaluation.
- Sports : Data analysis is used to gain insights into athlete performance, improve team strategy, and enhance fan engagement. This includes player evaluation, scouting analysis, and game strategy optimization.
- Marketing : Data analysis is used to measure the effectiveness of marketing campaigns, understand customer behavior, and develop targeted marketing strategies. This includes customer segmentation, marketing attribution analysis, and social media analytics.
- Environmental science : Data analysis is used to monitor and evaluate environmental conditions, assess the impact of human activities on the environment, and develop environmental policies. This includes climate modeling, ecological forecasting, and pollution monitoring.
When to Use Data Analysis
Data analysis is useful when you need to extract meaningful insights and information from large and complex datasets. It is a crucial step in the decision-making process, as it helps you understand the underlying patterns and relationships within the data, and identify potential areas for improvement or opportunities for growth.
Here are some specific scenarios where data analysis can be particularly helpful:
- Problem-solving : When you encounter a problem or challenge, data analysis can help you identify the root cause and develop effective solutions.
- Optimization : Data analysis can help you optimize processes, products, or services to increase efficiency, reduce costs, and improve overall performance.
- Prediction: Data analysis can help you make predictions about future trends or outcomes, which can inform strategic planning and decision-making.
- Performance evaluation : Data analysis can help you evaluate the performance of a process, product, or service to identify areas for improvement and potential opportunities for growth.
- Risk assessment : Data analysis can help you assess and mitigate risks, whether it is financial, operational, or related to safety.
- Market research : Data analysis can help you understand customer behavior and preferences, identify market trends, and develop effective marketing strategies.
- Quality control: Data analysis can help you ensure product quality and customer satisfaction by identifying and addressing quality issues.
Purpose of Data Analysis
The primary purposes of data analysis can be summarized as follows:
- To gain insights: Data analysis allows you to identify patterns and trends in data, which can provide valuable insights into the underlying factors that influence a particular phenomenon or process.
- To inform decision-making: Data analysis can help you make informed decisions based on the information that is available. By analyzing data, you can identify potential risks, opportunities, and solutions to problems.
- To improve performance: Data analysis can help you optimize processes, products, or services by identifying areas for improvement and potential opportunities for growth.
- To measure progress: Data analysis can help you measure progress towards a specific goal or objective, allowing you to track performance over time and adjust your strategies accordingly.
- To identify new opportunities: Data analysis can help you identify new opportunities for growth and innovation by identifying patterns and trends that may not have been visible before.
Examples of Data Analysis
Some Examples of Data Analysis are as follows:
- Social Media Monitoring: Companies use data analysis to monitor social media activity in real-time to understand their brand reputation, identify potential customer issues, and track competitors. By analyzing social media data, businesses can make informed decisions on product development, marketing strategies, and customer service.
- Financial Trading: Financial traders use data analysis to make real-time decisions about buying and selling stocks, bonds, and other financial instruments. By analyzing real-time market data, traders can identify trends and patterns that help them make informed investment decisions.
- Traffic Monitoring : Cities use data analysis to monitor traffic patterns and make real-time decisions about traffic management. By analyzing data from traffic cameras, sensors, and other sources, cities can identify congestion hotspots and make changes to improve traffic flow.
- Healthcare Monitoring: Healthcare providers use data analysis to monitor patient health in real-time. By analyzing data from wearable devices, electronic health records, and other sources, healthcare providers can identify potential health issues and provide timely interventions.
- Online Advertising: Online advertisers use data analysis to make real-time decisions about advertising campaigns. By analyzing data on user behavior and ad performance, advertisers can make adjustments to their campaigns to improve their effectiveness.
- Sports Analysis : Sports teams use data analysis to make real-time decisions about strategy and player performance. By analyzing data on player movement, ball position, and other variables, coaches can make informed decisions about substitutions, game strategy, and training regimens.
- Energy Management : Energy companies use data analysis to monitor energy consumption in real-time. By analyzing data on energy usage patterns, companies can identify opportunities to reduce energy consumption and improve efficiency.
Characteristics of Data Analysis
Characteristics of Data Analysis are as follows:
- Objective : Data analysis should be objective and based on empirical evidence, rather than subjective assumptions or opinions.
- Systematic : Data analysis should follow a systematic approach, using established methods and procedures for collecting, cleaning, and analyzing data.
- Accurate : Data analysis should produce accurate results, free from errors and bias. Data should be validated and verified to ensure its quality.
- Relevant : Data analysis should be relevant to the research question or problem being addressed. It should focus on the data that is most useful for answering the research question or solving the problem.
- Comprehensive : Data analysis should be comprehensive and consider all relevant factors that may affect the research question or problem.
- Timely : Data analysis should be conducted in a timely manner, so that the results are available when they are needed.
- Reproducible : Data analysis should be reproducible, meaning that other researchers should be able to replicate the analysis using the same data and methods.
- Communicable : Data analysis should be communicated clearly and effectively to stakeholders and other interested parties. The results should be presented in a way that is understandable and useful for decision-making.
Advantages of Data Analysis
Advantages of Data Analysis are as follows:
- Better decision-making: Data analysis helps in making informed decisions based on facts and evidence, rather than intuition or guesswork.
- Improved efficiency: Data analysis can identify inefficiencies and bottlenecks in business processes, allowing organizations to optimize their operations and reduce costs.
- Increased accuracy: Data analysis helps to reduce errors and bias, providing more accurate and reliable information.
- Better customer service: Data analysis can help organizations understand their customers better, allowing them to provide better customer service and improve customer satisfaction.
- Competitive advantage: Data analysis can provide organizations with insights into their competitors, allowing them to identify areas where they can gain a competitive advantage.
- Identification of trends and patterns : Data analysis can identify trends and patterns in data that may not be immediately apparent, helping organizations to make predictions and plan for the future.
- Improved risk management : Data analysis can help organizations identify potential risks and take proactive steps to mitigate them.
- Innovation: Data analysis can inspire innovation and new ideas by revealing new opportunities or previously unknown correlations in data.
Limitations of Data Analysis
- Data quality: The quality of data can impact the accuracy and reliability of analysis results. If data is incomplete, inconsistent, or outdated, the analysis may not provide meaningful insights.
- Limited scope: Data analysis is limited by the scope of the data available. If data is incomplete or does not capture all relevant factors, the analysis may not provide a complete picture.
- Human error : Data analysis is often conducted by humans, and errors can occur in data collection, cleaning, and analysis.
- Cost : Data analysis can be expensive, requiring specialized tools, software, and expertise.
- Time-consuming : Data analysis can be time-consuming, especially when working with large datasets or conducting complex analyses.
- Overreliance on data: Data analysis should be complemented with human intuition and expertise. Overreliance on data can lead to a lack of creativity and innovation.
- Privacy concerns: Data analysis can raise privacy concerns if personal or sensitive information is used without proper consent or security measures.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Research Methodology – Types, Examples and...

Research Paper – Structure, Examples and Writing...

Dissertation vs Thesis – Key Differences

Data Verification – Process, Types and Examples

Textual Analysis – Types, Examples and Guide

Figures in Research Paper – Examples and Guide
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case AskWhy Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Data Analysis in Research: Types & Methods

Content Index
Why analyze data in research?
Types of data in research, finding patterns in the qualitative data, methods used for data analysis in qualitative research, preparing data for analysis, methods used for data analysis in quantitative research, considerations in research data analysis, what is data analysis in research.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense.
Three essential things occur during the data analysis process — the first is data organization . Summarization and categorization together contribute to becoming the second known method used for data reduction. It helps find patterns and themes in the data for easy identification and linking. The third and last way is data analysis – researchers do it in both top-down and bottom-up fashion.
LEARN ABOUT: Research Process Steps
On the other hand, Marshall and Rossman describe data analysis as a messy, ambiguous, and time-consuming but creative and fascinating process through which a mass of collected data is brought to order, structure and meaning.
We can say that “the data analysis and data interpretation is a process representing the application of deductive and inductive logic to the research and data analysis.”
Researchers rely heavily on data as they have a story to tell or research problems to solve. It starts with a question, and data is nothing but an answer to that question. But, what if there is no question to ask? Well! It is possible to explore data even without a problem – we call it ‘Data Mining’, which often reveals some interesting patterns within the data that are worth exploring.
Irrelevant to the type of data researchers explore, their mission and audiences’ vision guide them to find the patterns to shape the story they want to tell. One of the essential things expected from researchers while analyzing data is to stay open and remain unbiased toward unexpected patterns, expressions, and results. Remember, sometimes, data analysis tells the most unforeseen yet exciting stories that were not expected when initiating data analysis. Therefore, rely on the data you have at hand and enjoy the journey of exploratory research.
Create a Free Account
Every kind of data has a rare quality of describing things after assigning a specific value to it. For analysis, you need to organize these values, processed and presented in a given context, to make it useful. Data can be in different forms; here are the primary data types.
- Qualitative data: When the data presented has words and descriptions, then we call it qualitative data . Although you can observe this data, it is subjective and harder to analyze data in research, especially for comparison. Example: Quality data represents everything describing taste, experience, texture, or an opinion that is considered quality data. This type of data is usually collected through focus groups, personal qualitative interviews , qualitative observation or using open-ended questions in surveys.
- Quantitative data: Any data expressed in numbers of numerical figures are called quantitative data . This type of data can be distinguished into categories, grouped, measured, calculated, or ranked. Example: questions such as age, rank, cost, length, weight, scores, etc. everything comes under this type of data. You can present such data in graphical format, charts, or apply statistical analysis methods to this data. The (Outcomes Measurement Systems) OMS questionnaires in surveys are a significant source of collecting numeric data.
- Categorical data: It is data presented in groups. However, an item included in the categorical data cannot belong to more than one group. Example: A person responding to a survey by telling his living style, marital status, smoking habit, or drinking habit comes under the categorical data. A chi-square test is a standard method used to analyze this data.
Learn More : Examples of Qualitative Data in Education
Data analysis in qualitative research
Data analysis and qualitative data research work a little differently from the numerical data as the quality data is made up of words, descriptions, images, objects, and sometimes symbols. Getting insight from such complicated information is a complicated process. Hence it is typically used for exploratory research and data analysis .
Although there are several ways to find patterns in the textual information, a word-based method is the most relied and widely used global technique for research and data analysis. Notably, the data analysis process in qualitative research is manual. Here the researchers usually read the available data and find repetitive or commonly used words.
For example, while studying data collected from African countries to understand the most pressing issues people face, researchers might find “food” and “hunger” are the most commonly used words and will highlight them for further analysis.
LEARN ABOUT: Level of Analysis
The keyword context is another widely used word-based technique. In this method, the researcher tries to understand the concept by analyzing the context in which the participants use a particular keyword.
For example , researchers conducting research and data analysis for studying the concept of ‘diabetes’ amongst respondents might analyze the context of when and how the respondent has used or referred to the word ‘diabetes.’
The scrutiny-based technique is also one of the highly recommended text analysis methods used to identify a quality data pattern. Compare and contrast is the widely used method under this technique to differentiate how a specific text is similar or different from each other.
For example: To find out the “importance of resident doctor in a company,” the collected data is divided into people who think it is necessary to hire a resident doctor and those who think it is unnecessary. Compare and contrast is the best method that can be used to analyze the polls having single-answer questions types .
Metaphors can be used to reduce the data pile and find patterns in it so that it becomes easier to connect data with theory.
Variable Partitioning is another technique used to split variables so that researchers can find more coherent descriptions and explanations from the enormous data.
LEARN ABOUT: Qualitative Research Questions and Questionnaires
There are several techniques to analyze the data in qualitative research, but here are some commonly used methods,
- Content Analysis: It is widely accepted and the most frequently employed technique for data analysis in research methodology. It can be used to analyze the documented information from text, images, and sometimes from the physical items. It depends on the research questions to predict when and where to use this method.
- Narrative Analysis: This method is used to analyze content gathered from various sources such as personal interviews, field observation, and surveys . The majority of times, stories, or opinions shared by people are focused on finding answers to the research questions.
- Discourse Analysis: Similar to narrative analysis, discourse analysis is used to analyze the interactions with people. Nevertheless, this particular method considers the social context under which or within which the communication between the researcher and respondent takes place. In addition to that, discourse analysis also focuses on the lifestyle and day-to-day environment while deriving any conclusion.
- Grounded Theory: When you want to explain why a particular phenomenon happened, then using grounded theory for analyzing quality data is the best resort. Grounded theory is applied to study data about the host of similar cases occurring in different settings. When researchers are using this method, they might alter explanations or produce new ones until they arrive at some conclusion.
LEARN ABOUT: 12 Best Tools for Researchers
Data analysis in quantitative research
The first stage in research and data analysis is to make it for the analysis so that the nominal data can be converted into something meaningful. Data preparation consists of the below phases.
Phase I: Data Validation
Data validation is done to understand if the collected data sample is per the pre-set standards, or it is a biased data sample again divided into four different stages
- Fraud: To ensure an actual human being records each response to the survey or the questionnaire
- Screening: To make sure each participant or respondent is selected or chosen in compliance with the research criteria
- Procedure: To ensure ethical standards were maintained while collecting the data sample
- Completeness: To ensure that the respondent has answered all the questions in an online survey. Else, the interviewer had asked all the questions devised in the questionnaire.
Phase II: Data Editing
More often, an extensive research data sample comes loaded with errors. Respondents sometimes fill in some fields incorrectly or sometimes skip them accidentally. Data editing is a process wherein the researchers have to confirm that the provided data is free of such errors. They need to conduct necessary checks and outlier checks to edit the raw edit and make it ready for analysis.
Phase III: Data Coding
Out of all three, this is the most critical phase of data preparation associated with grouping and assigning values to the survey responses . If a survey is completed with a 1000 sample size, the researcher will create an age bracket to distinguish the respondents based on their age. Thus, it becomes easier to analyze small data buckets rather than deal with the massive data pile.
LEARN ABOUT: Steps in Qualitative Research
After the data is prepared for analysis, researchers are open to using different research and data analysis methods to derive meaningful insights. For sure, statistical analysis plans are the most favored to analyze numerical data. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities. The method is again classified into two groups. First, ‘Descriptive Statistics’ used to describe data. Second, ‘Inferential statistics’ that helps in comparing the data .
Descriptive statistics
This method is used to describe the basic features of versatile types of data in research. It presents the data in such a meaningful way that pattern in the data starts making sense. Nevertheless, the descriptive analysis does not go beyond making conclusions. The conclusions are again based on the hypothesis researchers have formulated so far. Here are a few major types of descriptive analysis methods.
Measures of Frequency
- Count, Percent, Frequency
- It is used to denote home often a particular event occurs.
- Researchers use it when they want to showcase how often a response is given.
Measures of Central Tendency
- Mean, Median, Mode
- The method is widely used to demonstrate distribution by various points.
- Researchers use this method when they want to showcase the most commonly or averagely indicated response.
Measures of Dispersion or Variation
- Range, Variance, Standard deviation
- Here the field equals high/low points.
- Variance standard deviation = difference between the observed score and mean
- It is used to identify the spread of scores by stating intervals.
- Researchers use this method to showcase data spread out. It helps them identify the depth until which the data is spread out that it directly affects the mean.
Measures of Position
- Percentile ranks, Quartile ranks
- It relies on standardized scores helping researchers to identify the relationship between different scores.
- It is often used when researchers want to compare scores with the average count.
For quantitative research use of descriptive analysis often give absolute numbers, but the in-depth analysis is never sufficient to demonstrate the rationale behind those numbers. Nevertheless, it is necessary to think of the best method for research and data analysis suiting your survey questionnaire and what story researchers want to tell. For example, the mean is the best way to demonstrate the students’ average scores in schools. It is better to rely on the descriptive statistics when the researchers intend to keep the research or outcome limited to the provided sample without generalizing it. For example, when you want to compare average voting done in two different cities, differential statistics are enough.
Descriptive analysis is also called a ‘univariate analysis’ since it is commonly used to analyze a single variable.
Inferential statistics
Inferential statistics are used to make predictions about a larger population after research and data analysis of the representing population’s collected sample. For example, you can ask some odd 100 audiences at a movie theater if they like the movie they are watching. Researchers then use inferential statistics on the collected sample to reason that about 80-90% of people like the movie.
Here are two significant areas of inferential statistics.
- Estimating parameters: It takes statistics from the sample research data and demonstrates something about the population parameter.
- Hypothesis test: I t’s about sampling research data to answer the survey research questions. For example, researchers might be interested to understand if the new shade of lipstick recently launched is good or not, or if the multivitamin capsules help children to perform better at games.
These are sophisticated analysis methods used to showcase the relationship between different variables instead of describing a single variable. It is often used when researchers want something beyond absolute numbers to understand the relationship between variables.
Here are some of the commonly used methods for data analysis in research.
- Correlation: When researchers are not conducting experimental research or quasi-experimental research wherein the researchers are interested to understand the relationship between two or more variables, they opt for correlational research methods.
- Cross-tabulation: Also called contingency tables, cross-tabulation is used to analyze the relationship between multiple variables. Suppose provided data has age and gender categories presented in rows and columns. A two-dimensional cross-tabulation helps for seamless data analysis and research by showing the number of males and females in each age category.
- Regression analysis: For understanding the strong relationship between two variables, researchers do not look beyond the primary and commonly used regression analysis method, which is also a type of predictive analysis used. In this method, you have an essential factor called the dependent variable. You also have multiple independent variables in regression analysis. You undertake efforts to find out the impact of independent variables on the dependent variable. The values of both independent and dependent variables are assumed as being ascertained in an error-free random manner.
- Frequency tables: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Analysis of variance: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Researchers must have the necessary research skills to analyze and manipulation the data , Getting trained to demonstrate a high standard of research practice. Ideally, researchers must possess more than a basic understanding of the rationale of selecting one statistical method over the other to obtain better data insights.
- Usually, research and data analytics projects differ by scientific discipline; therefore, getting statistical advice at the beginning of analysis helps design a survey questionnaire, select data collection methods , and choose samples.
LEARN ABOUT: Best Data Collection Tools
- The primary aim of data research and analysis is to derive ultimate insights that are unbiased. Any mistake in or keeping a biased mind to collect data, selecting an analysis method, or choosing audience sample il to draw a biased inference.
- Irrelevant to the sophistication used in research data and analysis is enough to rectify the poorly defined objective outcome measurements. It does not matter if the design is at fault or intentions are not clear, but lack of clarity might mislead readers, so avoid the practice.
- The motive behind data analysis in research is to present accurate and reliable data. As far as possible, avoid statistical errors, and find a way to deal with everyday challenges like outliers, missing data, data altering, data mining , or developing graphical representation.
LEARN MORE: Descriptive Research vs Correlational Research The sheer amount of data generated daily is frightening. Especially when data analysis has taken center stage. in 2018. In last year, the total data supply amounted to 2.8 trillion gigabytes. Hence, it is clear that the enterprises willing to survive in the hypercompetitive world must possess an excellent capability to analyze complex research data, derive actionable insights, and adapt to the new market needs.
LEARN ABOUT: Average Order Value
QuestionPro is an online survey platform that empowers organizations in data analysis and research and provides them a medium to collect data by creating appealing surveys.
MORE LIKE THIS

Cross-Cultural Research: Methods, Challenges, & Key Findings
Aug 27, 2024

Qualtrics vs Microsoft Forms: Platform Comparison 2024

Are We Asking the Right Things at the Right Time in the Right Way? — Tuesday CX Thoughts

Jotform vs Microsoft Forms: Which Should You Choose?
Aug 26, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Tuesday CX Thoughts (TCXT)
- Uncategorized
- What’s Coming Up
- Workforce Intelligence

Data Analysis
Methodology chapter of your dissertation should include discussions about the methods of data analysis. You have to explain in a brief manner how you are going to analyze the primary data you will collect employing the methods explained in this chapter.
There are differences between qualitative data analysis and quantitative data analysis . In qualitative researches using interviews, focus groups, experiments etc. data analysis is going to involve identifying common patterns within the responses and critically analyzing them in order to achieve research aims and objectives.
Data analysis for quantitative studies, on the other hand, involves critical analysis and interpretation of figures and numbers, and attempts to find rationale behind the emergence of main findings. Comparisons of primary research findings to the findings of the literature review are critically important for both types of studies – qualitative and quantitative.
Data analysis methods in the absence of primary data collection can involve discussing common patterns, as well as, controversies within secondary data directly related to the research area.

John Dudovskiy
- University Libraries
- Research Guides
- Topic Guides
- Research Methods Guide
- Data Analysis
Research Methods Guide: Data Analysis
- Introduction
- Research Design & Method
- Survey Research
- Interview Research
- Resources & Consultation
Tools for Analyzing Survey Data
- R (open source)
- Stata
- DataCracker (free up to 100 responses per survey)
- SurveyMonkey (free up to 100 responses per survey)
Tools for Analyzing Interview Data
- AQUAD (open source)
- NVivo
Data Analysis and Presentation Techniques that Apply to both Survey and Interview Research
- Create a documentation of the data and the process of data collection.
- Analyze the data rather than just describing it - use it to tell a story that focuses on answering the research question.
- Use charts or tables to help the reader understand the data and then highlight the most interesting findings.
- Don’t get bogged down in the detail - tell the reader about the main themes as they relate to the research question, rather than reporting everything that survey respondents or interviewees said.
- State that ‘most people said …’ or ‘few people felt …’ rather than giving the number of people who said a particular thing.
- Use brief quotes where these illustrate a particular point really well.
- Respect confidentiality - you could attribute a quote to 'a faculty member', ‘a student’, or 'a customer' rather than ‘Dr. Nicholls.'
Survey Data Analysis
- If you used an online survey, the software will automatically collate the data – you will just need to download the data, for example as a spreadsheet.
- If you used a paper questionnaire, you will need to manually transfer the responses from the questionnaires into a spreadsheet. Put each question number as a column heading, and use one row for each person’s answers. Then assign each possible answer a number or ‘code’.
- When all the data is present and correct, calculate how many people selected each response.
- Once you have calculated how many people selected each response, you can set up tables and/or graph to display the data. This could take the form of a table or chart.
- In addition to descriptive statistics that characterize findings from your survey, you can use statistical and analytical reporting techniques if needed.
Interview Data Analysis
- Data Reduction and Organization: Try not to feel overwhelmed by quantity of information that has been collected from interviews- a one-hour interview can generate 20 to 25 pages of single-spaced text. Once you start organizing your fieldwork notes around themes, you can easily identify which part of your data to be used for further analysis.
- What were the main issues or themes that struck you in this contact / interviewee?"
- Was there anything else that struck you as salient, interesting, illuminating or important in this contact / interviewee?
- What information did you get (or failed to get) on each of the target questions you had for this contact / interviewee?
- Connection of the data: You can connect data around themes and concepts - then you can show how one concept may influence another.
- Examination of Relationships: Examining relationships is the centerpiece of the analytic process, because it allows you to move from simple description of the people and settings to explanations of why things happened as they did with those people in that setting.
- << Previous: Interview Research
- Next: Resources & Consultation >>
- Last Updated: Aug 21, 2023 10:42 AM
- History & Society
- Science & Tech
- Biographies
- Animals & Nature
- Geography & Travel
- Arts & Culture
- Games & Quizzes
- On This Day
- One Good Fact
- New Articles
- Lifestyles & Social Issues
- Philosophy & Religion
- Politics, Law & Government
- World History
- Health & Medicine
- Browse Biographies
- Birds, Reptiles & Other Vertebrates
- Bugs, Mollusks & Other Invertebrates
- Environment
- Fossils & Geologic Time
- Entertainment & Pop Culture
- Sports & Recreation
- Visual Arts
- Demystified
- Image Galleries
- Infographics
- Top Questions
- Britannica Kids
- Saving Earth
- Space Next 50
- Student Center
- Introduction
Data collection

data analysis
Our editors will review what you’ve submitted and determine whether to revise the article.
- Academia - Data Analysis
- U.S. Department of Health and Human Services - Office of Research Integrity - Data Analysis
- Chemistry LibreTexts - Data Analysis
- IBM - What is Exploratory Data Analysis?
- Table Of Contents

data analysis , the process of systematically collecting, cleaning, transforming, describing, modeling, and interpreting data , generally employing statistical techniques. Data analysis is an important part of both scientific research and business, where demand has grown in recent years for data-driven decision making . Data analysis techniques are used to gain useful insights from datasets, which can then be used to make operational decisions or guide future research . With the rise of “ big data ,” the storage of vast quantities of data in large databases and data warehouses, there is increasing need to apply data analysis techniques to generate insights about volumes of data too large to be manipulated by instruments of low information-processing capacity.
Datasets are collections of information. Generally, data and datasets are themselves collected to help answer questions, make decisions, or otherwise inform reasoning. The rise of information technology has led to the generation of vast amounts of data of many kinds, such as text, pictures, videos, personal information, account data, and metadata, the last of which provide information about other data. It is common for apps and websites to collect data about how their products are used or about the people using their platforms. Consequently, there is vastly more data being collected today than at any other time in human history. A single business may track billions of interactions with millions of consumers at hundreds of locations with thousands of employees and any number of products. Analyzing that volume of data is generally only possible using specialized computational and statistical techniques.
The desire for businesses to make the best use of their data has led to the development of the field of business intelligence , which covers a variety of tools and techniques that allow businesses to perform data analysis on the information they collect.
For data to be analyzed, it must first be collected and stored. Raw data must be processed into a format that can be used for analysis and be cleaned so that errors and inconsistencies are minimized. Data can be stored in many ways, but one of the most useful is in a database . A database is a collection of interrelated data organized so that certain records (collections of data related to a single entity) can be retrieved on the basis of various criteria . The most familiar kind of database is the relational database , which stores data in tables with rows that represent records (tuples) and columns that represent fields (attributes). A query is a command that retrieves a subset of the information in the database according to certain criteria. A query may retrieve only records that meet certain criteria, or it may join fields from records across multiple tables by use of a common field.
Frequently, data from many sources is collected into large archives of data called data warehouses. The process of moving data from its original sources (such as databases) to a centralized location (generally a data warehouse) is called ETL (which stands for extract , transform , and load ).
- The extraction step occurs when you identify and copy or export the desired data from its source, such as by running a database query to retrieve the desired records.
- The transformation step is the process of cleaning the data so that they fit the analytical need for the data and the schema of the data warehouse. This may involve changing formats for certain fields, removing duplicate records, or renaming fields, among other processes.
- Finally, the clean data are loaded into the data warehouse, where they may join vast amounts of historical data and data from other sources.
After data are effectively collected and cleaned, they can be analyzed with a variety of techniques. Analysis often begins with descriptive and exploratory data analysis. Descriptive data analysis uses statistics to organize and summarize data, making it easier to understand the broad qualities of the dataset. Exploratory data analysis looks for insights into the data that may arise from descriptions of distribution, central tendency, or variability for a single data field. Further relationships between data may become apparent by examining two fields together. Visualizations may be employed during analysis, such as histograms (graphs in which the length of a bar indicates a quantity) or stem-and-leaf plots (which divide data into buckets, or “stems,” with individual data points serving as “leaves” on the stem).

Data analysis frequently goes beyond descriptive analysis to predictive analysis, making predictions about the future using predictive modeling techniques. Predictive modeling uses machine learning , regression analysis methods (which mathematically calculate the relationship between an independent variable and a dependent variable), and classification techniques to identify trends and relationships among variables. Predictive analysis may involve data mining , which is the process of discovering interesting or useful patterns in large volumes of information. Data mining often involves cluster analysis , which tries to find natural groupings within data, and anomaly detection , which detects instances in data that are unusual and stand out from other patterns. It may also look for rules within datasets, strong relationships among variables in the data.
Research Guide: Data analysis and reporting findings
- Postgraduate Online Training subject guide This link opens in a new window
- Open Educational Resources (OERs)
- Library support
- Research ideas
- You and your supervisor
- Researcher skills
- Research Data Management This link opens in a new window
- Literature review
- Plagiarism This link opens in a new window
- Research Methods
- Data analysis and reporting findings
- Statistical support
- Writing support
- Researcher visibility
- Conferences and Presentations
- Postgraduate Forums
- Soft skills development
- Emotional support
- The Commons Informer (blog)
- Research Tip Archives
- RC Newsletter Archives
- Evaluation Forms
- Editing FAQs
Data analysis and findings
Data analysis is the most crucial part of any research. Data analysis summarizes collected data. It involves the interpretation of data gathered through the use of analytical and logical reasoning to determine patterns, relationships or trends.
Data Analysis Checklist
Cleaning data
* Did you capture and code your data in the right manner?
*Do you have all data or missing data?
* Do you have enough observations?
* Do you have any outliers? If yes, what is the remedy for outlier?
* Does your data have the potential to answer your questions?
Analyzing data
* Visualize your data, e.g. charts, tables, and graphs, to mention a few.
* Identify patterns, correlations, and trends
* Test your hypotheses
* Let your data tell a story
Reports the results
* Communicate and interpret the results
* Conclude and recommend
* Your targeted audience must understand your results
* Use more datasets and samples
* Use accessible and understandable data analytical tool
* Do not delegate your data analysis
* Clean data to confirm that they are complete and free from errors
* Analyze cleaned data
* Understand your results
* Keep in mind who will be reading your results and present it in a way that they will understand it
* Share the results with the supervisor oftentimes
Past presentations
- PhD Writing Retreat - Analysing_Fieldwork_Data by Cori Wielenga A clear and concise presentation on the ‘now what’ and ‘so what’ of data collection and analysis - compiled and originally presented by Cori Wielenga.
Online Resources

- Qualitative analysis of interview data: A step-by-step guide
- Qualitative Data Analysis - Coding & Developing Themes
Beginner's Guide to SPSS
- SPSS Guideline for Beginners Presented by Hennie Gerber
Recommended Quantitative Data Analysis books

Recommended Qualitative Data Analysis books

- << Previous: Data collection techniques
- Next: Statistical support >>
- Last Updated: Aug 23, 2024 12:44 PM
- URL: https://library.up.ac.za/c.php?g=485435

Research Methods
- Getting Started
- What is Research Design?
- Research Approach
- Research Methodology
- Data Collection
- Data Analysis & Interpretation
- Population & Sampling
- Theories, Theoretical Perspective & Theoretical Framework
- Useful Resources
Further Resources

Data Analysis & Interpretation
- Quantitative Data
Qualitative Data
- Mixed Methods
You will need to tidy, analyse and interpret the data you collected to give meaning to it, and to answer your research question. Your choice of methodology points the way to the most suitable method of analysing your data.

If the data is numeric you can use a software package such as SPSS, Excel Spreadsheet or “R” to do statistical analysis. You can identify things like mean, median and average or identify a causal or correlational relationship between variables.
The University of Connecticut has useful information on statistical analysis.
If your research set out to test a hypothesis your research will either support or refute it, and you will need to explain why this is the case. You should also highlight and discuss any issues or actions that may have impacted on your results, either positively or negatively. To fully contribute to the body of knowledge in your area be sure to discuss and interpret your results within the context of your research and the existing literature on the topic.
Data analysis for a qualitative study can be complex because of the variety of types of data that can be collected. Qualitative researchers aren’t attempting to measure observable characteristics, they are often attempting to capture an individual’s interpretation of a phenomena or situation in a particular context or setting. This data could be captured in text from an interview or focus group, a movie, images, or documents. Analysis of this type of data is usually done by analysing each artefact according to a predefined and outlined criteria for analysis and then by using a coding system. The code can be developed by the researcher before analysis or the researcher may develop a code from the research data. This can be done by hand or by using thematic analysis software such as NVivo.
Interpretation of qualitative data can be presented as a narrative. The themes identified from the research can be organised and integrated with themes in the existing literature to give further weight and meaning to the research. The interpretation should also state if the aims and objectives of the research were met. Any shortcomings with research or areas for further research should also be discussed (Creswell,2009)*.
For further information on analysing and presenting qualitative date, read this article in Nature .
Mixed Methods Data
Data analysis for mixed methods involves aspects of both quantitative and qualitative methods. However, the sequencing of data collection and analysis is important in terms of the mixed method approach that you are taking. For example, you could be using a convergent, sequential or transformative model which directly impacts how you use different data to inform, support or direct the course of your study.
The intention in using mixed methods is to produce a synthesis of both quantitative and qualitative information to give a detailed picture of a phenomena in a particular context or setting. To fully understand how best to produce this synthesis it might be worth looking at why researchers choose this method. Bergin**(2018) states that researchers choose mixed methods because it allows them to triangulate, illuminate or discover a more diverse set of findings. Therefore, when it comes to interpretation you will need to return to the purpose of your research and discuss and interpret your data in that context. As with quantitative and qualitative methods, interpretation of data should be discussed within the context of the existing literature.
Bergin’s book is available in the Library to borrow. Bolton LTT collection 519.5 BER
Creswell’s book is available in the Library to borrow. Bolton LTT collection 300.72 CRE
For more information on data analysis look at Sage Research Methods database on the library website.
*Creswell, John W.(2009) Research design: qualitative, and mixed methods approaches. Sage, Los Angeles, pp 183
**Bergin, T (2018), Data analysis: quantitative, qualitative and mixed methods. Sage, Los Angeles, pp182
- << Previous: Data Collection
- Next: Population & Sampling >>
- Last Updated: Sep 7, 2023 3:09 PM
- URL: https://tudublin.libguides.com/research_methods
Data Analysis
- Introduction to Data Analysis
- Quantitative Analysis Tools
- Qualitative Analysis Tools
- Mixed Methods Analysis
- Geospatial Analysis
- Further Reading

What is Data Analysis?
According to the federal government, data analysis is "the process of systematically applying statistical and/or logical techniques to describe and illustrate, condense and recap, and evaluate data" ( Responsible Conduct in Data Management ). Important components of data analysis include searching for patterns, remaining unbiased in drawing inference from data, practicing responsible data management , and maintaining "honest and accurate analysis" ( Responsible Conduct in Data Management ).
In order to understand data analysis further, it can be helpful to take a step back and understand the question "What is data?". Many of us associate data with spreadsheets of numbers and values, however, data can encompass much more than that. According to the federal government, data is "The recorded factual material commonly accepted in the scientific community as necessary to validate research findings" ( OMB Circular 110 ). This broad definition can include information in many formats.
Some examples of types of data are as follows:
- Photographs
- Hand-written notes from field observation
- Machine learning training data sets
- Ethnographic interview transcripts
- Sheet music
- Scripts for plays and musicals
- Observations from laboratory experiments ( CMU Data 101 )
Thus, data analysis includes the processing and manipulation of these data sources in order to gain additional insight from data, answer a research question, or confirm a research hypothesis.
Data analysis falls within the larger research data lifecycle, as seen below.
( University of Virginia )
Why Analyze Data?
Through data analysis, a researcher can gain additional insight from data and draw conclusions to address the research question or hypothesis. Use of data analysis tools helps researchers understand and interpret data.
What are the Types of Data Analysis?
Data analysis can be quantitative, qualitative, or mixed methods.
Quantitative research typically involves numbers and "close-ended questions and responses" ( Creswell & Creswell, 2018 , p. 3). Quantitative research tests variables against objective theories, usually measured and collected on instruments and analyzed using statistical procedures ( Creswell & Creswell, 2018 , p. 4). Quantitative analysis usually uses deductive reasoning.
Qualitative research typically involves words and "open-ended questions and responses" ( Creswell & Creswell, 2018 , p. 3). According to Creswell & Creswell, "qualitative research is an approach for exploring and understanding the meaning individuals or groups ascribe to a social or human problem" ( 2018 , p. 4). Thus, qualitative analysis usually invokes inductive reasoning.
Mixed methods research uses methods from both quantitative and qualitative research approaches. Mixed methods research works under the "core assumption... that the integration of qualitative and quantitative data yields additional insight beyond the information provided by either the quantitative or qualitative data alone" ( Creswell & Creswell, 2018 , p. 4).
- Next: Planning >>
- Last Updated: Aug 20, 2024 3:01 PM
- URL: https://guides.library.georgetown.edu/data-analysis
Data Analysis in Quantitative Research
- Reference work entry
- First Online: 13 January 2019
- Cite this reference work entry

- Yong Moon Jung 2
2350 Accesses
2 Citations
Quantitative data analysis serves as part of an essential process of evidence-making in health and social sciences. It is adopted for any types of research question and design whether it is descriptive, explanatory, or causal. However, compared with qualitative counterpart, quantitative data analysis has less flexibility. Conducting quantitative data analysis requires a prerequisite understanding of the statistical knowledge and skills. It also requires rigor in the choice of appropriate analysis model and the interpretation of the analysis outcomes. Basically, the choice of appropriate analysis techniques is determined by the type of research question and the nature of the data. In addition, different analysis techniques require different assumptions of data. This chapter provides introductory guides for readers to assist them with their informed decision-making in choosing the correct analysis models. To this end, it begins with discussion of the levels of measure: nominal, ordinal, and scale. Some commonly used analysis techniques in univariate, bivariate, and multivariate data analysis are presented for practical examples. Example analysis outcomes are produced by the use of SPSS (Statistical Package for Social Sciences).
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Similar content being viewed by others

Data Analysis Techniques for Quantitative Study

Meta-Analytic Methods for Public Health Research
Armstrong JS. Significance tests harm progress in forecasting. Int J Forecast. 2007;23(2):321–7.
Article Google Scholar
Babbie E. The practice of social research. 14th ed. Belmont: Cengage Learning; 2016.
Google Scholar
Brockopp DY, Hastings-Tolsma MT. Fundamentals of nursing research. Boston: Jones & Bartlett; 2003.
Creswell JW. Research design: qualitative, quantitative, and mixed methods approaches. Thousand Oaks: Sage; 2014.
Fawcett J. The relationship of theory and research. Philadelphia: F. A. Davis; 1999.
Field A. Discovering statistics using IBM SPSS statistics. London: Sage; 2013.
Grove SK, Gray JR, Burns N. Understanding nursing research: building an evidence-based practice. 6th ed. St. Louis: Elsevier Saunders; 2015.
Hair JF, Black WC, Babin BJ, Anderson RE, Tatham RD. Multivariate data analysis. Upper Saddle River: Pearson Prentice Hall; 2006.
Katz MH. Multivariable analysis: a practical guide for clinicians. Cambridge: Cambridge University Press; 2006.
Book Google Scholar
McHugh ML. Scientific inquiry. J Specialists Pediatr Nurs. 2007; 8 (1):35–7. Volume 8, Issue 1, Version of Record online: 22 FEB 2007
Pallant J. SPSS survival manual: a step by step guide to data analysis using IBM SPSS. Sydney: Allen & Unwin; 2016.
Polit DF, Beck CT. Nursing research: principles and methods. Philadelphia: Lippincott Williams & Wilkins; 2004.
Trochim WMK, Donnelly JP. Research methods knowledge base. 3rd ed. Mason: Thomson Custom Publishing; 2007.
Tabachnick, B. G., & Fidell, L. S. (2013). Using multivariate statistics. Boston: Pearson Education.
Wells CS, Hin JM. Dealing with assumptions underlying statistical tests. Psychol Sch. 2007;44(5):495–502.
Download references
Author information
Authors and affiliations.
Centre for Business and Social Innovation, University of Technology Sydney, Ultimo, NSW, Australia
Yong Moon Jung
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Yong Moon Jung .
Editor information
Editors and affiliations.
School of Science and Health, Western Sydney University, Penrith, NSW, Australia
Pranee Liamputtong
Rights and permissions
Reprints and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this entry
Cite this entry.
Jung, Y.M. (2019). Data Analysis in Quantitative Research. In: Liamputtong, P. (eds) Handbook of Research Methods in Health Social Sciences. Springer, Singapore. https://doi.org/10.1007/978-981-10-5251-4_109
Download citation
DOI : https://doi.org/10.1007/978-981-10-5251-4_109
Published : 13 January 2019
Publisher Name : Springer, Singapore
Print ISBN : 978-981-10-5250-7
Online ISBN : 978-981-10-5251-4
eBook Packages : Social Sciences Reference Module Humanities and Social Sciences Reference Module Business, Economics and Social Sciences
Share this entry
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
The 7 Most Useful Data Analysis Methods and Techniques
Data analytics is the process of analyzing raw data to draw out meaningful insights. These insights are then used to determine the best course of action.
When is the best time to roll out that marketing campaign? Is the current team structure as effective as it could be? Which customer segments are most likely to purchase your new product?
Ultimately, data analytics is a crucial driver of any successful business strategy. But how do data analysts actually turn raw data into something useful? There are a range of methods and techniques that data analysts use depending on the type of data in question and the kinds of insights they want to uncover.
You can get a hands-on introduction to data analytics in this free short course .
In this post, we’ll explore some of the most useful data analysis techniques. By the end, you’ll have a much clearer idea of how you can transform meaningless data into business intelligence. We’ll cover:
- What is data analysis and why is it important?
- What is the difference between qualitative and quantitative data?
- Regression analysis
- Monte Carlo simulation
- Factor analysis
- Cohort analysis
- Cluster analysis
- Time series analysis
- Sentiment analysis
- The data analysis process
- The best tools for data analysis
- Key takeaways
The first six methods listed are used for quantitative data , while the last technique applies to qualitative data. We briefly explain the difference between quantitative and qualitative data in section two, but if you want to skip straight to a particular analysis technique, just use the clickable menu.
1. What is data analysis and why is it important?
Data analysis is, put simply, the process of discovering useful information by evaluating data. This is done through a process of inspecting, cleaning, transforming, and modeling data using analytical and statistical tools, which we will explore in detail further along in this article.
Why is data analysis important? Analyzing data effectively helps organizations make business decisions. Nowadays, data is collected by businesses constantly: through surveys, online tracking, online marketing analytics, collected subscription and registration data (think newsletters), social media monitoring, among other methods.
These data will appear as different structures, including—but not limited to—the following:
The concept of big data —data that is so large, fast, or complex, that it is difficult or impossible to process using traditional methods—gained momentum in the early 2000s. Then, Doug Laney, an industry analyst, articulated what is now known as the mainstream definition of big data as the three Vs: volume, velocity, and variety.
- Volume: As mentioned earlier, organizations are collecting data constantly. In the not-too-distant past it would have been a real issue to store, but nowadays storage is cheap and takes up little space.
- Velocity: Received data needs to be handled in a timely manner. With the growth of the Internet of Things, this can mean these data are coming in constantly, and at an unprecedented speed.
- Variety: The data being collected and stored by organizations comes in many forms, ranging from structured data—that is, more traditional, numerical data—to unstructured data—think emails, videos, audio, and so on. We’ll cover structured and unstructured data a little further on.
This is a form of data that provides information about other data, such as an image. In everyday life you’ll find this by, for example, right-clicking on a file in a folder and selecting “Get Info”, which will show you information such as file size and kind, date of creation, and so on.
Real-time data
This is data that is presented as soon as it is acquired. A good example of this is a stock market ticket, which provides information on the most-active stocks in real time.
Machine data
This is data that is produced wholly by machines, without human instruction. An example of this could be call logs automatically generated by your smartphone.
Quantitative and qualitative data
Quantitative data—otherwise known as structured data— may appear as a “traditional” database—that is, with rows and columns. Qualitative data—otherwise known as unstructured data—are the other types of data that don’t fit into rows and columns, which can include text, images, videos and more. We’ll discuss this further in the next section.
2. What is the difference between quantitative and qualitative data?
How you analyze your data depends on the type of data you’re dealing with— quantitative or qualitative . So what’s the difference?
Quantitative data is anything measurable , comprising specific quantities and numbers. Some examples of quantitative data include sales figures, email click-through rates, number of website visitors, and percentage revenue increase. Quantitative data analysis techniques focus on the statistical, mathematical, or numerical analysis of (usually large) datasets. This includes the manipulation of statistical data using computational techniques and algorithms. Quantitative analysis techniques are often used to explain certain phenomena or to make predictions.
Qualitative data cannot be measured objectively , and is therefore open to more subjective interpretation. Some examples of qualitative data include comments left in response to a survey question, things people have said during interviews, tweets and other social media posts, and the text included in product reviews. With qualitative data analysis, the focus is on making sense of unstructured data (such as written text, or transcripts of spoken conversations). Often, qualitative analysis will organize the data into themes—a process which, fortunately, can be automated.
Data analysts work with both quantitative and qualitative data , so it’s important to be familiar with a variety of analysis methods. Let’s take a look at some of the most useful techniques now.
3. Data analysis techniques
Now we’re familiar with some of the different types of data, let’s focus on the topic at hand: different methods for analyzing data.
a. Regression analysis
Regression analysis is used to estimate the relationship between a set of variables. When conducting any type of regression analysis , you’re looking to see if there’s a correlation between a dependent variable (that’s the variable or outcome you want to measure or predict) and any number of independent variables (factors which may have an impact on the dependent variable). The aim of regression analysis is to estimate how one or more variables might impact the dependent variable, in order to identify trends and patterns. This is especially useful for making predictions and forecasting future trends.
Let’s imagine you work for an ecommerce company and you want to examine the relationship between: (a) how much money is spent on social media marketing, and (b) sales revenue. In this case, sales revenue is your dependent variable—it’s the factor you’re most interested in predicting and boosting. Social media spend is your independent variable; you want to determine whether or not it has an impact on sales and, ultimately, whether it’s worth increasing, decreasing, or keeping the same. Using regression analysis, you’d be able to see if there’s a relationship between the two variables. A positive correlation would imply that the more you spend on social media marketing, the more sales revenue you make. No correlation at all might suggest that social media marketing has no bearing on your sales. Understanding the relationship between these two variables would help you to make informed decisions about the social media budget going forward. However: It’s important to note that, on their own, regressions can only be used to determine whether or not there is a relationship between a set of variables—they don’t tell you anything about cause and effect. So, while a positive correlation between social media spend and sales revenue may suggest that one impacts the other, it’s impossible to draw definitive conclusions based on this analysis alone.
There are many different types of regression analysis, and the model you use depends on the type of data you have for the dependent variable. For example, your dependent variable might be continuous (i.e. something that can be measured on a continuous scale, such as sales revenue in USD), in which case you’d use a different type of regression analysis than if your dependent variable was categorical in nature (i.e. comprising values that can be categorised into a number of distinct groups based on a certain characteristic, such as customer location by continent). You can learn more about different types of dependent variables and how to choose the right regression analysis in this guide .
Regression analysis in action: Investigating the relationship between clothing brand Benetton’s advertising expenditure and sales
b. Monte Carlo simulation
When making decisions or taking certain actions, there are a range of different possible outcomes. If you take the bus, you might get stuck in traffic. If you walk, you might get caught in the rain or bump into your chatty neighbor, potentially delaying your journey. In everyday life, we tend to briefly weigh up the pros and cons before deciding which action to take; however, when the stakes are high, it’s essential to calculate, as thoroughly and accurately as possible, all the potential risks and rewards.
Monte Carlo simulation, otherwise known as the Monte Carlo method, is a computerized technique used to generate models of possible outcomes and their probability distributions. It essentially considers a range of possible outcomes and then calculates how likely it is that each particular outcome will be realized. The Monte Carlo method is used by data analysts to conduct advanced risk analysis, allowing them to better forecast what might happen in the future and make decisions accordingly.
So how does Monte Carlo simulation work, and what can it tell us? To run a Monte Carlo simulation, you’ll start with a mathematical model of your data—such as a spreadsheet. Within your spreadsheet, you’ll have one or several outputs that you’re interested in; profit, for example, or number of sales. You’ll also have a number of inputs; these are variables that may impact your output variable. If you’re looking at profit, relevant inputs might include the number of sales, total marketing spend, and employee salaries. If you knew the exact, definitive values of all your input variables, you’d quite easily be able to calculate what profit you’d be left with at the end. However, when these values are uncertain, a Monte Carlo simulation enables you to calculate all the possible options and their probabilities. What will your profit be if you make 100,000 sales and hire five new employees on a salary of $50,000 each? What is the likelihood of this outcome? What will your profit be if you only make 12,000 sales and hire five new employees? And so on. It does this by replacing all uncertain values with functions which generate random samples from distributions determined by you, and then running a series of calculations and recalculations to produce models of all the possible outcomes and their probability distributions. The Monte Carlo method is one of the most popular techniques for calculating the effect of unpredictable variables on a specific output variable, making it ideal for risk analysis.
Monte Carlo simulation in action: A case study using Monte Carlo simulation for risk analysis
c. Factor analysis
Factor analysis is a technique used to reduce a large number of variables to a smaller number of factors. It works on the basis that multiple separate, observable variables correlate with each other because they are all associated with an underlying construct. This is useful not only because it condenses large datasets into smaller, more manageable samples, but also because it helps to uncover hidden patterns. This allows you to explore concepts that cannot be easily measured or observed—such as wealth, happiness, fitness, or, for a more business-relevant example, customer loyalty and satisfaction.
Let’s imagine you want to get to know your customers better, so you send out a rather long survey comprising one hundred questions. Some of the questions relate to how they feel about your company and product; for example, “Would you recommend us to a friend?” and “How would you rate the overall customer experience?” Other questions ask things like “What is your yearly household income?” and “How much are you willing to spend on skincare each month?”
Once your survey has been sent out and completed by lots of customers, you end up with a large dataset that essentially tells you one hundred different things about each customer (assuming each customer gives one hundred responses). Instead of looking at each of these responses (or variables) individually, you can use factor analysis to group them into factors that belong together—in other words, to relate them to a single underlying construct. In this example, factor analysis works by finding survey items that are strongly correlated. This is known as covariance . So, if there’s a strong positive correlation between household income and how much they’re willing to spend on skincare each month (i.e. as one increases, so does the other), these items may be grouped together. Together with other variables (survey responses), you may find that they can be reduced to a single factor such as “consumer purchasing power”. Likewise, if a customer experience rating of 10/10 correlates strongly with “yes” responses regarding how likely they are to recommend your product to a friend, these items may be reduced to a single factor such as “customer satisfaction”.
In the end, you have a smaller number of factors rather than hundreds of individual variables. These factors are then taken forward for further analysis, allowing you to learn more about your customers (or any other area you’re interested in exploring).
Factor analysis in action: Using factor analysis to explore customer behavior patterns in Tehran
d. Cohort analysis
Cohort analysis is a data analytics technique that groups users based on a shared characteristic , such as the date they signed up for a service or the product they purchased. Once users are grouped into cohorts, analysts can track their behavior over time to identify trends and patterns.
So what does this mean and why is it useful? Let’s break down the above definition further. A cohort is a group of people who share a common characteristic (or action) during a given time period. Students who enrolled at university in 2020 may be referred to as the 2020 cohort. Customers who purchased something from your online store via the app in the month of December may also be considered a cohort.
With cohort analysis, you’re dividing your customers or users into groups and looking at how these groups behave over time. So, rather than looking at a single, isolated snapshot of all your customers at a given moment in time (with each customer at a different point in their journey), you’re examining your customers’ behavior in the context of the customer lifecycle. As a result, you can start to identify patterns of behavior at various points in the customer journey—say, from their first ever visit to your website, through to email newsletter sign-up, to their first purchase, and so on. As such, cohort analysis is dynamic, allowing you to uncover valuable insights about the customer lifecycle.
This is useful because it allows companies to tailor their service to specific customer segments (or cohorts). Let’s imagine you run a 50% discount campaign in order to attract potential new customers to your website. Once you’ve attracted a group of new customers (a cohort), you’ll want to track whether they actually buy anything and, if they do, whether or not (and how frequently) they make a repeat purchase. With these insights, you’ll start to gain a much better understanding of when this particular cohort might benefit from another discount offer or retargeting ads on social media, for example. Ultimately, cohort analysis allows companies to optimize their service offerings (and marketing) to provide a more targeted, personalized experience. You can learn more about how to run cohort analysis using Google Analytics .
Cohort analysis in action: How Ticketmaster used cohort analysis to boost revenue
e. Cluster analysis
Cluster analysis is an exploratory technique that seeks to identify structures within a dataset. The goal of cluster analysis is to sort different data points into groups (or clusters) that are internally homogeneous and externally heterogeneous. This means that data points within a cluster are similar to each other, and dissimilar to data points in another cluster. Clustering is used to gain insight into how data is distributed in a given dataset, or as a preprocessing step for other algorithms.
There are many real-world applications of cluster analysis. In marketing, cluster analysis is commonly used to group a large customer base into distinct segments, allowing for a more targeted approach to advertising and communication. Insurance firms might use cluster analysis to investigate why certain locations are associated with a high number of insurance claims. Another common application is in geology, where experts will use cluster analysis to evaluate which cities are at greatest risk of earthquakes (and thus try to mitigate the risk with protective measures).
It’s important to note that, while cluster analysis may reveal structures within your data, it won’t explain why those structures exist. With that in mind, cluster analysis is a useful starting point for understanding your data and informing further analysis. Clustering algorithms are also used in machine learning—you can learn more about clustering in machine learning in our guide .
Cluster analysis in action: Using cluster analysis for customer segmentation—a telecoms case study example
f. Time series analysis
Time series analysis is a statistical technique used to identify trends and cycles over time. Time series data is a sequence of data points which measure the same variable at different points in time (for example, weekly sales figures or monthly email sign-ups). By looking at time-related trends, analysts are able to forecast how the variable of interest may fluctuate in the future.
When conducting time series analysis, the main patterns you’ll be looking out for in your data are:
- Trends: Stable, linear increases or decreases over an extended time period.
- Seasonality: Predictable fluctuations in the data due to seasonal factors over a short period of time. For example, you might see a peak in swimwear sales in summer around the same time every year.
- Cyclic patterns: Unpredictable cycles where the data fluctuates. Cyclical trends are not due to seasonality, but rather, may occur as a result of economic or industry-related conditions.
As you can imagine, the ability to make informed predictions about the future has immense value for business. Time series analysis and forecasting is used across a variety of industries, most commonly for stock market analysis, economic forecasting, and sales forecasting. There are different types of time series models depending on the data you’re using and the outcomes you want to predict. These models are typically classified into three broad types: the autoregressive (AR) models, the integrated (I) models, and the moving average (MA) models. For an in-depth look at time series analysis, refer to our guide .
Time series analysis in action: Developing a time series model to predict jute yarn demand in Bangladesh
g. Sentiment analysis
When you think of data, your mind probably automatically goes to numbers and spreadsheets.
Many companies overlook the value of qualitative data, but in reality, there are untold insights to be gained from what people (especially customers) write and say about you. So how do you go about analyzing textual data?
One highly useful qualitative technique is sentiment analysis , a technique which belongs to the broader category of text analysis —the (usually automated) process of sorting and understanding textual data.
With sentiment analysis, the goal is to interpret and classify the emotions conveyed within textual data. From a business perspective, this allows you to ascertain how your customers feel about various aspects of your brand, product, or service.
There are several different types of sentiment analysis models, each with a slightly different focus. The three main types include:
Fine-grained sentiment analysis
If you want to focus on opinion polarity (i.e. positive, neutral, or negative) in depth, fine-grained sentiment analysis will allow you to do so.
For example, if you wanted to interpret star ratings given by customers, you might use fine-grained sentiment analysis to categorize the various ratings along a scale ranging from very positive to very negative.
Emotion detection
This model often uses complex machine learning algorithms to pick out various emotions from your textual data.
You might use an emotion detection model to identify words associated with happiness, anger, frustration, and excitement, giving you insight into how your customers feel when writing about you or your product on, say, a product review site.
Aspect-based sentiment analysis
This type of analysis allows you to identify what specific aspects the emotions or opinions relate to, such as a certain product feature or a new ad campaign.
If a customer writes that they “find the new Instagram advert so annoying”, your model should detect not only a negative sentiment, but also the object towards which it’s directed.
In a nutshell, sentiment analysis uses various Natural Language Processing (NLP) algorithms and systems which are trained to associate certain inputs (for example, certain words) with certain outputs.
For example, the input “annoying” would be recognized and tagged as “negative”. Sentiment analysis is crucial to understanding how your customers feel about you and your products, for identifying areas for improvement, and even for averting PR disasters in real-time!
Sentiment analysis in action: 5 Real-world sentiment analysis case studies
4. The data analysis process
In order to gain meaningful insights from data, data analysts will perform a rigorous step-by-step process. We go over this in detail in our step by step guide to the data analysis process —but, to briefly summarize, the data analysis process generally consists of the following phases:
Defining the question
The first step for any data analyst will be to define the objective of the analysis, sometimes called a ‘problem statement’. Essentially, you’re asking a question with regards to a business problem you’re trying to solve. Once you’ve defined this, you’ll then need to determine which data sources will help you answer this question.
Collecting the data
Now that you’ve defined your objective, the next step will be to set up a strategy for collecting and aggregating the appropriate data. Will you be using quantitative (numeric) or qualitative (descriptive) data? Do these data fit into first-party, second-party, or third-party data?
Learn more: Quantitative vs. Qualitative Data: What’s the Difference?
Cleaning the data
Unfortunately, your collected data isn’t automatically ready for analysis—you’ll have to clean it first. As a data analyst, this phase of the process will take up the most time. During the data cleaning process, you will likely be:
- Removing major errors, duplicates, and outliers
- Removing unwanted data points
- Structuring the data—that is, fixing typos, layout issues, etc.
- Filling in major gaps in data
Analyzing the data
Now that we’ve finished cleaning the data, it’s time to analyze it! Many analysis methods have already been described in this article, and it’s up to you to decide which one will best suit the assigned objective. It may fall under one of the following categories:
- Descriptive analysis , which identifies what has already happened
- Diagnostic analysis , which focuses on understanding why something has happened
- Predictive analysis , which identifies future trends based on historical data
- Prescriptive analysis , which allows you to make recommendations for the future
Visualizing and sharing your findings
We’re almost at the end of the road! Analyses have been made, insights have been gleaned—all that remains to be done is to share this information with others. This is usually done with a data visualization tool, such as Google Charts, or Tableau.
Learn more: 13 of the Most Common Types of Data Visualization
To sum up the process, Will’s explained it all excellently in the following video:
5. The best tools for data analysis
As you can imagine, every phase of the data analysis process requires the data analyst to have a variety of tools under their belt that assist in gaining valuable insights from data. We cover these tools in greater detail in this article , but, in summary, here’s our best-of-the-best list, with links to each product:
The top 9 tools for data analysts
- Microsoft Excel
- Jupyter Notebook
- Apache Spark
- Microsoft Power BI
6. Key takeaways and further reading
As you can see, there are many different data analysis techniques at your disposal. In order to turn your raw data into actionable insights, it’s important to consider what kind of data you have (is it qualitative or quantitative?) as well as the kinds of insights that will be useful within the given context. In this post, we’ve introduced seven of the most useful data analysis techniques—but there are many more out there to be discovered!
So what now? If you haven’t already, we recommend reading the case studies for each analysis technique discussed in this post (you’ll find a link at the end of each section). For a more hands-on introduction to the kinds of methods and techniques that data analysts use, try out this free introductory data analytics short course. In the meantime, you might also want to read the following:
- The Best Online Data Analytics Courses for 2024
- What Is Time Series Data and How Is It Analyzed?
- What is Spatial Analysis?
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|

IMAGES
COMMENTS
By learning foundational data analysis methods, you can develop the ability to assess and analyze your data accurately, leading to informed insights within your industry. As you begin, start by learning key techniques such as regression, hypothesis, and cluster analysis. ... Learners are advised to conduct additional research to ensure that ...
No method can guarantee absolute certainty, but regression analysis offers a reliable framework for forecasting future trends based on past data. Companies can apply this method to anticipate future sales for financial planning purposes and predict inventory requirements for more efficient space and cost management.
Introduction While there is an interest in defining longitudinal change in people with chronic illness like Parkinson's disease (PD), statistical analysis of longitudinal data is not straightforward for clinical researchers. Here, we aim to demonstrate how the choice of statistical method may influence research outcomes, (e.g., progression in apathy), specifically the size of longitudinal ...
Methods. A cross-sectional study was conducted in the East Wollega zone, Oromia Regional State, Ethiopia. Ethiopian fiscal year of 2021-2022 data was collected from August 01-30, 2022 and 34 health centers (decision-making units) were included in the analysis. Data envelope analysis was used to analyze the technical efficiency.
A thorough analysis of LEACH successor clustering protocols is presented in this survey. The present research is the first research to categorise routing procedures based on LEACH into three groups: data transmission, CH selection, and combining data transmission and "cluster head" (CH) selection strategies.
The ideal worker norm is associated with specific ways of working. The ideal worker is a man who works long hours, is constantly available, and highly productive. Emerging research suggests that the shock of COVID‐19, which forced millions of employees to work from home, may have been powerful enough to disrupt the ideal worker norm. We therefore ask: how did working from home during the ...
It was the highest rent level seen in our data history and was $967 (40.1%) higher than five years ago. ... Methodology. New York City rental data as of July 2024 for all units advertised as for ...
Retrieval-Augmented Generation (RAG) has emerged as a crucial method for addressing hallucinations in large language models (LLMs). While recent research has extended RAG models to complex noisy scenarios, these explorations often confine themselves to limited noise types and presuppose that noise is inherently detrimental to LLMs, potentially deviating from real-world retrieval environments ...
Data Analysis. Definition: Data analysis refers to the process of inspecting, cleaning, transforming, and modeling data with the goal of discovering useful information, drawing conclusions, and supporting decision-making. It involves applying various statistical and computational techniques to interpret and derive insights from large datasets.
Methods used for data analysis in qualitative research. There are several techniques to analyze the data in qualitative research, but here are some commonly used methods, Content Analysis: It is widely accepted and the most frequently employed technique for data analysis in research methodology. It can be used to analyze the documented ...
Below we present a step-by-step guide for analysing data for two different types of research questions. The data analysis methods described here are based on basic content analysis as described by Elo and Kyngäs 4 and Graneheim and Lundman, 5 and the integrative review as described by Whittemore and Knafl, 6 but modified to be applicable to ...
Data analysis is simply the process of converting the gathered data to meanin gf ul information. Different techniques such as modeling to reach trends, relatio nships, and therefore conclusions to ...
There are differences between qualitative data analysis and quantitative data analysis. In qualitative researches using interviews, focus groups, experiments etc. data analysis is going to involve identifying common patterns within the responses and critically analyzing them in order to achieve research aims and objectives. Data analysis for ...
Data Analysis and Presentation Techniques that Apply to both Survey and Interview Research. Create a documentation of the data and the process of data collection. Analyze the data rather than just describing it - use it to tell a story that focuses on answering the research question. Use charts or tables to help the reader understand the data ...
The SAGE Handbook of. tive Data AnalysisUwe FlickMapping the FieldData analys. s is the central step in qualitative research. Whatever the data are, it is their analysis that, in a de. isive way, forms the outcomes of the research. Sometimes, data collection is limited to recording and docu-menting naturally occurring ph.
Written by Coursera Staff • Updated on Apr 19, 2024. Data analysis is the practice of working with data to glean useful information, which can then be used to make informed decisions. "It is a capital mistake to theorize before one has data. Insensibly one begins to twist facts to suit theories, instead of theories to suit facts," Sherlock ...
exploratory data analysis. data analysis, the process of systematically collecting, cleaning, transforming, describing, modeling, and interpreting data, generally employing statistical techniques. Data analysis is an important part of both scientific research and business, where demand has grown in recent years for data-driven decision making.
Jessica Nina Lester is an associate professor of Counseling and Educational Psychology at Indiana University. She received her PhD from the University of Tennessee, Knoxville. Her research strand focuses on the study and development of qualitative research methodologies and methods at a theoretical, conceptual, and technical level.
Statistical methods involved in carrying out a study include planning, designing, collecting data, analysing, drawing meaningful interpretation and reporting of the research findings. The statistical analysis gives meaning to the meaningless numbers, thereby breathing life into a lifeless data. The results and inferences are precise only if ...
The research design is a fundamental aspect of research methodology, outlining the overall strategy and structure of the study. It includes decisions regarding the research type (e.g., descriptive, experimental), the selection of variables, and the determination of the study's scope and timeframe. We must carefully consider the design to ...
Data analysis is the most crucial part of any research. Data analysis summarizes collected data. It involves the interpretation of data gathered through the use of analytical and logical reasoning to determine patterns, relationships or trends. ... and several triangulative and mixed-method research designs. This volume is recommended for ...
For more information on data analysis look at Sage Research Methods database on the library website. *Creswell, John W.(2009) Research design: qualitative, and mixed methods approaches. Sage, Los Angeles, pp 183 **Bergin, T (2018), Data analysis: quantitative, qualitative and mixed methods. Sage, Los Angeles, pp182 <<
Data analysis can be quantitative, qualitative, or mixed methods. Quantitative research typically involves numbers and "close-ended questions and responses" (Creswell & Creswell, 2018, p. 3).Quantitative research tests variables against objective theories, usually measured and collected on instruments and analyzed using statistical procedures (Creswell & Creswell, 2018, p. 4).
There should be a section on the chosen methodology and a brief discussion about why qualitative methodology was most appropriate for the study question and why one particular methodology (e.g., interpretative phenomenological analysis rather than grounded theory) was selected to guide the research. The method itself should then be described ...
Quantitative data analysis is an essential process that supports decision-making and evidence-based research in health and social sciences. Compared with qualitative counterpart, quantitative data analysis has less flexibility (see Chaps. 48, "Thematic Analysis," 49, "Narrative Analysis," 28, "Conversation Analysis: An Introduction to Methodology, Data Collection, and Analysis ...
Often, qualitative analysis will organize the data into themes—a process which, fortunately, can be automated. Data analysts work with both quantitative and qualitative data, so it's important to be familiar with a variety of analysis methods. Let's take a look at some of the most useful techniques now. 3. Data analysis techniques
These are just a few examples of the data analysis methods you can use. Your choice should depend on the nature of the data, the research question or problem, and the desired outcome. How to Analyze Data. Analyzing data involves following a systematic approach to extract insights and derive meaningful conclusions. Here are some steps to guide ...
Data Analysis is the process of systematically applying statistical and/or logical techniques to describe and illustrate, condense and recap, and evaluate data. According to Shamoo and Resnik (2003) various analytic procedures "provide a way of drawing inductive inferences from data and distinguishing the signal (the phenomenon of interest) from the noise (statistical fluctuations) present ...
Research methods are specific procedures for collecting and analyzing data. Developing your research methods is an integral part of your research design. When planning your methods, there are two key decisions you will make. First, decide how you will collect data. Your methods depend on what type of data you need to answer your research question:
Books. Research Methodology and Data Analysis Second Edition. Zainudin Awang. UiTM Press, 2012 - Education - 334 pages. This book provides proper direction in doing research especially towards the understanding of research objectives, and research hypotheses. The book also guides in research methodology such as the methods of designing a ...